Path Analysis (LT2)
Preliminaries
library(OpenMx)
library(lavaan)
library(semPlot)
library(tidyverse)
library(mice)
library(MoEClust)
library(performance)
library(mediation)
library(Hmisc) What is path analysis?
Path analysis sounds scary at first. But it is just a extension of linear regression, so we know the underlying math already! An extension where multiple observed variables can be considered as ‘outcomes’, rather than just one as is the case in the GLM.
As we saw in the lecture, this makes path analysis a multivariate analysis: one that can include multiple outcomes to test theoretical models. We can also apply rules of parsimony (leaving redundant paths out of the model) and adjudicate the ‘fit’ of overidentified models. It is indeed an elegant analysis for many reasons.
Before we begin getting to grips with path analysis, there are a few assumtions of path analysis. Some the same as the GLM assumptions, and some different. These are:
All causal relationships between variables must go in one direction only (you cannot have a pair of variables that cause each other).
The variables must have a clear time-ordering since one variable cannot be said to cause another unless it precedes it in time.
The path model variables share linear relationships and don’t interact with each other (linearity).
Residuals (i.e., prediction errors) aren’t correlated with predictor variables (independence) or each other (normality), and residuals have constant variance across values of your predictor variables (equality of variance).
Measurements are valid and reliable. We can account for invalidity and unreliability in structural equation modeling, but not path analysis.]
The path model accounts for all relevant influences on the variables included. All models are wrong, but how wrong is yours?
Path analysis is theoretically useful because, unlike GLM, it forces us to specify the relationships with think are operating among all of the variables. This results in models showing causal mechanisms through which independent variables produce both direct and indirect effects on a dependent variable. It also means we can leave redundant paths out of the analysis, which is something we cannot do in multiple linear regression.
We tested mediation last year, and if you recall, we had to do this with multiple regression models estimating the a, b, c, and c’ paths. Path analysis allows us to test these paths simultaneously and omit any paths we think are redundant (ie., the direct effect)
Mainly, we will focus on how path models can be conducted simply as a series of regressions in the R package lavaan, including estimation of indirect effects with bootstrapping. We are armed with knowledge of the GLM, indirect effects, and bootstrapping, so we are well placed to tackle this topic!
How to use path analysis
Typically path analysis involves the construction of a path diagram in which the relationships between all variables and the causal direction between them are specifically laid out.
When conducting path analysis one should first construct an input path diagram, which illustrates the hypothesized relationships. After statistical analysis has been completed, an output path diagram can then be constructed, which illustrates the relationships as they actually exist, according to the analysis conducted.
Just like regression, while path analysis is useful for evaluating causal hypotheses, this method cannot determine causality. It clarifies correlation and indicates the adequacy of a theoretical model, but does not prove direction or causation.
We can test two types of model:
- Over identified: A model with missing parameters (i.e., has degrees of freedom)

- Just identified: A model with all parameters (i.e., has no degrees of freedom)

Multiple regression models are just identified. You can run them as a path model, sure, but you’ll get the same answer. We ran a just identified mediation model last year when we tested mediation.
The point of running an over identified path model - or any structural equation model for that matter - is to be able to be wrong. And that’s only true if your model is over identified (i.e. has missing paths).
If a model is over identified, then it has more than one solution, all of which are equally good.
Here’s an equation:
x=5
There is one unknown, and one equation. It is just identified. That’s fine if you want to know the value of x, but there is no way that the model can be wrong. Just like there is no way a model specifying all possible paths can be wrong. It will replicate the covariance matrix perfectly.
Here’s another:
x+y=5
There are two unknowns and one equation. It’s over identified. There are an several solutions and they are all equally good.
Here’s a set of equations. There are two unknowns and two equations, it’s just identified.
x+y=5 x−y=1
Just identified because there are two unknowns and two equations (i.e., no degrees of freedom)
Finally:
x+y=5 x−y=1 2x+2y=6
Now there are three equations, and two unknowns. It’s now possible for this set of equations to be wrong, and they are wrong. But change that value of 6, and the model could be correct, and still be over identified.
So we want over identified models, because they provide a single solution that can possibly be wrong. Just identified models also provide a single solution, but they cannot be wrong.
So why is this a good thing? Why don’t we just test just identified models? Well, its sort of like when somebody tells you that you have a right to be sued. That’s weird a thing to say to someone. Why would anyone want to be able to be sued? Surely you’d be happier if you couldn’t be sued?
The ability to be sued, however, means that people can trust you with things because they can sue you if you screw up. You can rent a car, get a bank account, sign a contract, get a credit card. People who can’t be sued, like children, can’t do those things. In the same way, being able to be wrong has advantages: if you’re right, it’s better evidence for your theory (because you could have been wrong but you weren’t!). If you are wrong, though, the theory needs refinement.
Path analysis is all about theory testing and the ability to be wrong is central to that goal.
Today’s data
To practice conducting path analysis, we are going to use data from research on a sample of 213 call center employees. The focus of this research was to better understand how and why employees were burnout out and what were the potential causes or triggers.
This work surveyed employees on several theoretically relevant managerial behaviors and psychological mediators. In the data are variables drawn from several scales of interest:
- Controlling Manager Behavior Scale (CMBS; Bartholomew et al., 2010).
This measure assesses perceived provision of psychological control from managers. An example item from this instrument is: “my manager pays me less attention if I have displeased them”. Participants indicated the extent to which they believed each of 4 items on a 7-point Likert-type scale ranging from 1 (not at all true) to 7 (very true) to be true. The 4 items have been averaged to yield a manager control variable called “Control”.
- Psychological Disconnection Scale (PDS; Bartholomew et al., 2011).
This measure assesses employees’ perceived sense of disconnection at work. An example item from this instrument is: “I feel others at work can be dismissive of me.” Participants indicated the extent to which they believed each of 12 items on a 7-point Likert-type scale ranging from 1 (not at all true) to 7 (very true) to be true. The 12 items have been averaged to yield a disconnection variable called “Disconnection”.
- Work Burnout Questionnaire (WBQ, exhaustion subscale; Masasch).
This measure assessed employees’ perceived exhaustion at work. An example item from this instrument is: “I feel physically worn out at work” Participants indicated the experiences of each of 5 items on a 5-point Likert-type scale ranging from 1 (almost never) to 7 (almost always). The 5 items have been averaged to yield an exhaustion variable called “Exhaustion”.
Load data
First, lets load this data into our R environment. Go to the LT2 folder, and then to the workshop folder, and find the “employee.csv” file. Click on it and then select “import dataset”. In the new window that appears, click “update” and then when the dataframe shows, click import. If you want, you can try running the code below and it might do the same thing (if not put your hand up).
employee <- read_csv("C:/Users/CURRANT/Dropbox/Work/LSE/PB230/LT2/Workshop/employee.csv")##
## -- Column specification ---------------------------------------------------------------------
## cols(
## ID = col_double(),
## Structure = col_double(),
## Control = col_double(),
## Exhaustion = col_double(),
## Disconnection = col_double(),
## Gender = col_character()
## )employee## # A tibble: 213 x 6
## ID Structure Control Exhaustion Disconnection Gender
## <dbl> <dbl> <dbl> <dbl> <dbl> <chr>
## 1 122 5.38 2.25 5 4.92 Female
## 2 6 4.75 5.25 4.6 4.86 Male
## 3 78 4.5 3 4.2 5.42 Male
## 4 89 7 3 4.2 2 Female
## 5 61 4.12 3.25 4 3 Male
## 6 67 5.25 3.25 4 3.67 Male
## 7 143 6 2 4 3.08 Female
## 8 121 5.25 2.25 3.8 3.58 Female
## 9 1 4.71 6.25 3.6 3.17 Male
## 10 44 4.62 3.75 3.6 1.83 Male
## # ... with 203 more rowsWith this data we are going to test for the mediation of disconnection on the relationship between manager control and exhaustion using path analysis. We did the same test last year using multiple regression. As I mentioned earlier, there is nothing new here as regards the the underlying analytic framework. It’s just regression!
A quick overview of the research question
The research question we are going to address is whether employee exhaustion can be explained by manager control through perceptions of disconnection.
The theory - and this is important - is that manager behavior can impact on levels of exhaustion but that the relationship is indirect. That is, it goes through a third variable. In this case, we think that controlling behavior by managers contributes to exhaustion BECUASE those behaviors foster a sense of disconnection at work.
This is a classic case of mediation. The relationship between the predictor and outcome is hypothesized to be transmitted through the mediator.
Recall from last year that to test for mediation, we need to test 3 effects: (1) direct, (2) total, and (3) indirect. The latter, indirect effect, is the focal effect in mediation analysis because it quantifies the predictor’s effect on the outcome through the mechanism represented by the mediator. In other words, it is the product of the indirect regression coefficients that link the predictor with the outcome.
Hypothetically, then, we can leave out the direct effect and total effects from the model and just test the focal indirect effect. We have no way of doing this with multiple regression because all paths must be tested (i.e., no degrees of freedom) - but we can do it with path analysis!
As always, before we delve into this topic lets just clarify the research question and null hypothesis we are testing:
Research Question - Is the relationship between manager control and employee exhastion mediated by disconnection?
Null Hypothesis - The indirect effect of the relationship between manager control and employee exhaustion through disconnection will be zero.
Screening and Cleaning
Lets briefly check the data for missing values and outliers, as all good data scientists should before any analysis.
First missing value analysis using MICE:
## missing data
data_var <-
employee %>%
dplyr::select(3:5) # select out only the items
md.pattern(data_var)## /\ /\
## { `---' }
## { O O }
## ==> V <== No need for mice. This data set is completely observed.
## \ \|/ /
## `-----'
## Control Exhaustion Disconnection
## 213 1 1 1 0
## 0 0 0 0Great no missing values. Now for univariate outliers:
# Standardize variables
data_var$zControl <- scale(data_var$Control)
data_var$zExhaustion <- scale(data_var$Exhaustion)
data_var$zDisconnection <- scale(data_var$Disconnection)
# Remove Control outliers
data_var <-
data_var %>%
filter(zControl >= -3.30 & zControl <= 3.30)
# Remove Exhaustion outliers
data_var <-
data_var %>%
filter(zExhaustion >= -3.30 & zExhaustion <= 3.30)
# Remove Disconnection outliers
data_var <-
data_var %>%
filter(zDisconnection >= -3.30 & zDisconnection <= 3.30)Okay, we had one outlier there so it is removed. Finally, multivariate outliers:
# build linear model
linear.model <- lm(Exhaustion ~ Control + Disconnection, data=data_var)
# save residuals
data_var$res <- data_var$Exhaustion - predict(linear.model)
# save mahalabonus distances
data_var$mahal <- MoE_mahala(linear.model, data_var$res)Find the critical value of chi square for the numerator (model) degrees of freedom (2) of the linear model at p = .001 and remove multivariate outliers. It happens to be 13.82.
# Remove multivariate outliers
data_var <-
data_var %>%
filter(mahal <= 13.82)Great, no multivariate outliers. We are good to go.
Model assumptions
Now lets quickly check the visuals for the model assumptions using the performance function we saw last week.
check_model(linear.model)## `geom_smooth()` using formula 'y ~ x'
## `geom_smooth()` using formula 'y ~ x'
## `geom_smooth()` using formula 'y ~ x'## `stat_bin()` using `bins = 30`. Pick better value with `binwidth`.## Warning: Removed 212 rows containing missing values (geom_text_repel).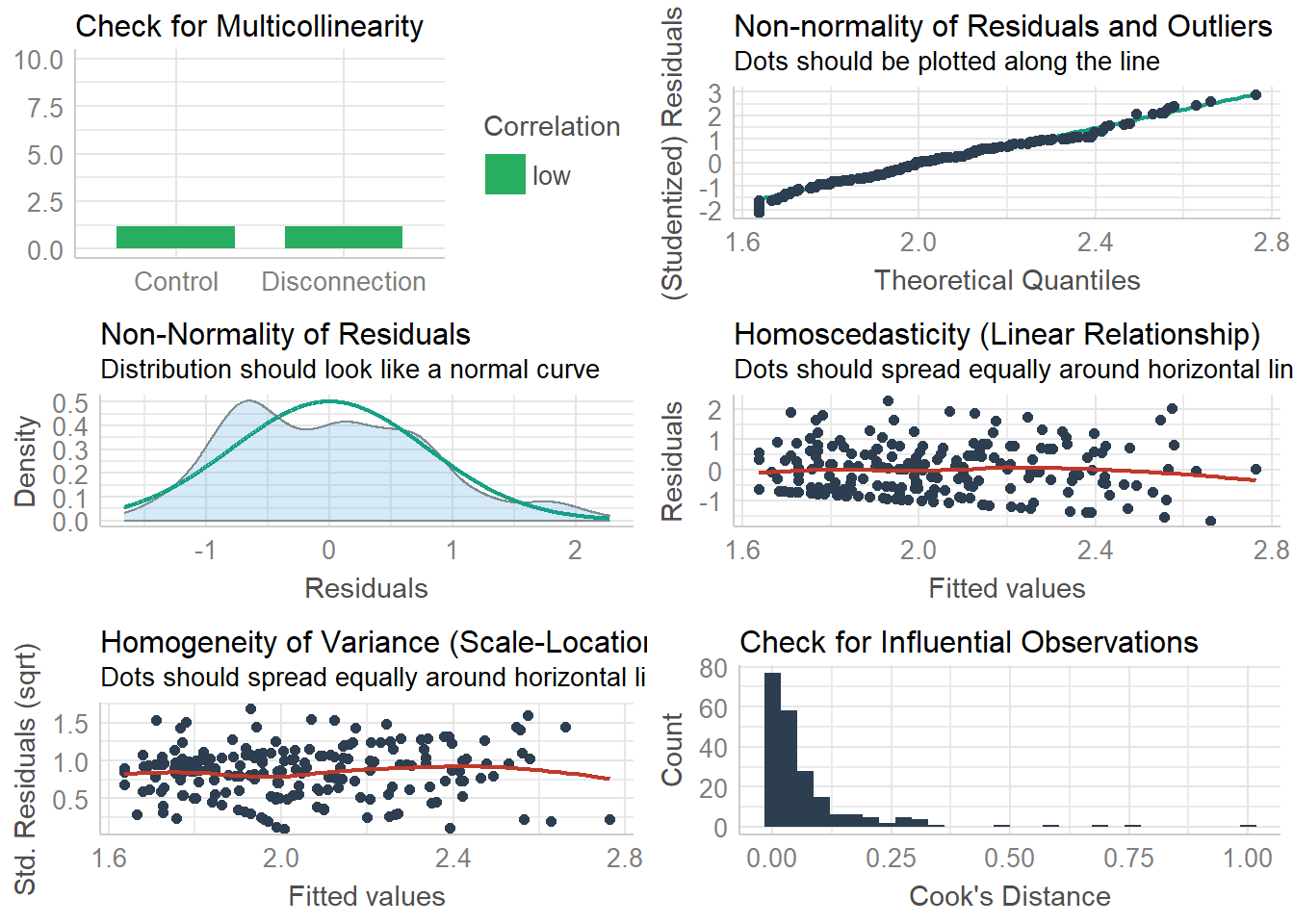
Looks pretty good to me! Let’s crack onward.
Correlations
As always with any regression-based analysis, it is important to begin by inspecting the correlations between the variable. This is especially important in path analysis - or any structural equation model for that matter - because the correlation matrix is the baseline to which our hypothesized models are compared.
The central question is: how well does our model’s correlation matrix approximate the actual correlation matrix? If there is a close match, the model is good. If there is a discrepancy, then our model is missing information and needs refinement.
As we saw in the lecture, path analysis is part of the set of techniques often termed ‘covariance modelling’. As the name implies the primary focus here is the relationships between variables, and less so the mean-structure of the variables (as in sum of squares). In fact, by default R first creates the correlation matrix of all the variables in the model, and the fit is based only on these values, plus the sample sizes (in early SEM software you typically had to provide the correlation matrix directly, rather than working with the raw data). So the correlations are what R is working with to compute the coefficients and model fit using Wright’s tracing rules, as we saw in the lecture. Pretty neat.
Let’s quickly run the correlation matrix now for the variables:
rcorr(as.matrix(data_var[,c("Control","Disconnection", "Exhaustion")], type="pearson"))## Control Disconnection Exhaustion
## Control 1.00 0.37 0.18
## Disconnection 0.37 1.00 0.29
## Exhaustion 0.18 0.29 1.00
##
## n= 212
##
##
## P
## Control Disconnection Exhaustion
## Control 0.0000 0.0085
## Disconnection 0.0000 0.0000
## Exhaustion 0.0085 0.0000We can see that, in line with our hypotheses, the variables are all positively correlated. That’s good. It will be the job of our model testing to attempt to approximate this matrix. In just identified models, we will perfectly replicate this matrix because no information is missing (ie. 0 degrees of freedom). In over identified models there will be some discrepancy because information is missing.
Building path models in lavaan
To define a path model, lavaan requires that you specify the relationships between variables in a text format. A full guide to this lavaan model syntax is available on the project website here: https://lavaan.ugent.be/tutorial/syntax1.html
For path mediation models the format is very simple, and resembles a series of linear models, written over several lines, but in text rather than as a model formula:
# define the model over multiple lines for clarity
mediation.model <- "
y ~ x + m
m ~ x
"In this case the ~ symbols just means ‘regressed on’ or ‘is predicted by’. The model in the example above defines that our outcome y is predicted by both x and m, and that x also predicts m. In the multiple regression, the independent variables are separated by the “+” operator, just like the lm() function.
You might recognize this as a mediation model. Thats because it is!
Another feature of path modelling in lavaan that differs from the lm function is the operation must be enclosed within quotes (").
So make sure you include the closing quote symbol, and also be careful when running the code which defines the model. RStudio can sometimes gets confused and only runs some of the lines, leading to errors. The simplest solution is to select the entire block explicitly and run that.
To fit the model we pass the model specification and the data to the sem() function (sem means structural equation modeling):
# mediation.fit <- sem(mediation.model, data=dat)As we did for linear regression models, we save the model fit object into a variable, here named mediation.fit.
Also the linear model function we can display the model results using summary(). The key section of the output to check is the table listed ‘Regressions’, which lists the regression parameters for the predictors for each of the endogenous variables. Lets go ahead and apply this knowledge to our mediation model.
The just identified mediation model
To begin with, lets write the code that builds the just identified mediation model. That is, the model which contain all possible paths. It is also the model that directly mimics the linear regression approach we ran last year, as we will see later.

A couple of addition things to note:
Within the mediation models, I label coefficients a, b and c with the astrix (*).
You can use “:=” to define a new parameter, such as the indirect effect (ab). Note when you define new parameter with :=, you can use the astrix to multiply values. This is very useful for mediation models becuase the indirect effect is a multiplied by b.
I also request the total effect here, which you will recall is the indirect effect plus the direct effect.
med.model <- "
# the c and b paths
Exhaustion ~ c * Control + b * Disconnection
# the a path
Disconnection ~ a * Control
# indirect and total effects
ab := a*b
total := ab+c
"Now we have set up the path model, we can fit it using the sem function. Before we do that though, one thing to note about the standard errors for the estimates.
Paths and standard errors in lavaan are by default estimated using maximum likelihood estimation. We saw MLE this last year when we introduced logistic regression as a method for estimating the maximum liklihood line of best fit in the absence of residuals. The same logic applies in path analysis (and structural equation modeling more generally) because the input for path modeling is the covariance matrix, not the data. Therefore we have no residuals to estimate error with, we need another method and that method is MLE.
Remember: we are using the correlations to estimate the paths, not the data (this is also why there are no intercepts reported in SEM, because unlike linear regression, the means are not used). With full information (i.e., no degrees of freedom), we can estimate the correlations perfectly. But when we remove information, as we will do later, our estimates will be wrong, how how wrong is the question.
All this means that in addition to MLE we should estimate the error in our estimates another way. A way that is perhaps more intuitive to us. As we have been doing to date, I suggest we use bootstrapping, which behave exactly the same way as it does in linear regression (i.e., resampling and estimating the error, then resampling and estimating the error, and so on).
To extract bootstrapped SE’s, we simply add the command se = “boot”, and can then also specify the number of boostrap’s we want with bootstrap = x (we will set it to 5,000, as we normally do).
Okay, lets go ahead and set that up:
just.model <- sem(med.model, data = data_var, se = "bootstrap", bootstrap = 100)As we did for linear regression models, we have saved the model fit object into a variable, here named just.model.
To display the model results we can use summary(), again just like the linear model. However, we need some critical output that isn’t provided by default in the lavaan summary, so we need to specifically ask for it. The things we need:
We want to obtain the confidence intervals for our different effects, so in the summary statement, we can include ‘ci=TRUE.’
We also want standardized estimates (based on the correlations) as well as the unstandardised estimates (based on the covariances). So in the summary statement, we can include ‘standardized=TRUE’.
We also want the fit indexes of our model to tell us how well the model fits to the data. For a just identified model like this one, the fit will be perfect (i.e., 0 degrees of freedom). But these indexes will come in very handy as we move to over identified models. For the fit indexes, in the summary statement we can include ‘fit.measures=TRUE’.
summary(just.model, fit.measures=TRUE, standardized=TRUE, ci=TRUE)## lavaan 0.6-7 ended normally after 14 iterations
##
## Estimator ML
## Optimization method NLMINB
## Number of free parameters 5
##
## Number of observations 212
##
## Model Test User Model:
##
## Test statistic 0.000
## Degrees of freedom 0
##
## Model Test Baseline Model:
##
## Test statistic 51.347
## Degrees of freedom 3
## P-value 0.000
##
## User Model versus Baseline Model:
##
## Comparative Fit Index (CFI) 1.000
## Tucker-Lewis Index (TLI) 1.000
##
## Loglikelihood and Information Criteria:
##
## Loglikelihood user model (H0) -577.450
## Loglikelihood unrestricted model (H1) -577.450
##
## Akaike (AIC) 1164.899
## Bayesian (BIC) 1181.682
## Sample-size adjusted Bayesian (BIC) 1165.839
##
## Root Mean Square Error of Approximation:
##
## RMSEA 0.000
## 90 Percent confidence interval - lower 0.000
## 90 Percent confidence interval - upper 0.000
## P-value RMSEA <= 0.05 NA
##
## Standardized Root Mean Square Residual:
##
## SRMR 0.000
##
## Parameter Estimates:
##
## Standard errors Bootstrap
## Number of requested bootstrap draws 100
## Number of successful bootstrap draws 100
##
## Regressions:
## Estimate Std.Err z-value P(>|z|) ci.lower ci.upper
## Exhaustion ~
## Control (c) 0.056 0.047 1.198 0.231 -0.025 0.165
## Disconnctn (b) 0.181 0.054 3.367 0.001 0.055 0.294
## Disconnection ~
## Control (a) 0.359 0.068 5.311 0.000 0.216 0.495
## Std.lv Std.all
##
## 0.056 0.084
## 0.181 0.261
##
## 0.359 0.369
##
## Variances:
## Estimate Std.Err z-value P(>|z|) ci.lower ci.upper
## .Exhaustion 0.632 0.052 12.086 0.000 0.513 0.744
## .Disconnection 1.259 0.101 12.421 0.000 1.053 1.461
## Std.lv Std.all
## 0.632 0.908
## 1.259 0.864
##
## Defined Parameters:
## Estimate Std.Err z-value P(>|z|) ci.lower ci.upper
## ab 0.065 0.023 2.793 0.005 0.018 0.113
## total 0.121 0.047 2.571 0.010 0.031 0.232
## Std.lv Std.all
## 0.065 0.096
## 0.121 0.180The important output from this table is the model fit indexes. One of the most important advantages of path analysis - and structural equation modeling more generally - is that it provides a test of the overall model (rather than individual coefficients). Here, goodness of fit tests determine if the model being tested should be accepted or rejected.
These overall fit tests do not establish that particular paths within the model are significant. If the model is accepted, the researcher will then go on to interpret the path coefficients in the model (“significant” path coefficients in poor fit models are not meaningful).
Model fit detour
lavaan prints several different goodness-of-fit measures, the choice of which is a matter of dispute among methodologists. Kline (1998) recommends at least four tests, such as chi-square; or CFI; TLI; and SRMR. My recommendation aligns with that of Kline (1998) with the addition of the RMSEA. Lets take a closer look at these indexes:
1. Model Chi-Square (χ2). Model chi-square, also called discrepancy or the discrepancy function, is the most common fit test, printed by all computer programs. R outputs it as the test statistic for the model test user model.
The chi-square value should not be significant if there is a good model fit, while a significant chi-square indicates lack of satisfactory model fit. That is, chi-square is a “badness of fit” measure in that a finding of significance means the given model’s implied covariance structure is significantly different from the observed sample covariance matrix.
If model chi-square < .05, the researcher’s model is rejected. BIG note of caution, though: there are three ways, listed below, in which the chi-square test may be misleading. Because of these reasons, many researchers believe that with a reasonable sample size (N > 200) and good approximate fit as indicated by other fit tests (e.g., CFI, TLI, RMSEA), the significance of the chi-square test may be discounted and that a significant chi-square is not a reason by itself to modify the model. Problems with the chi-square test:
The more complex the model, the more likely a good fit. In a just-identified model, with as many parameters as possible and still achieve a solution, there will be a perfect fit. Put another way, chi-square tests the difference between the researcher’s model and a just-identified version of it, so the closer the researcher’s model is to being just-identified, the more likely good fit will be found.
The larger the sample size, the more likely the rejection of the model and the more likely a Type II error (rejecting something true). In very large samples, even tiny differences between the observed model and the perfect-fit model may be found significant.
The chi-square fit index is also very sensitive to violations of the assumption of multivariate normality. When this assumption is known to be violated, chi-square is a poor indicator of fit.
2. Comparative Fit Index (CFI). CFI compares the existing model fit with a null model which assumes the variables in the model are uncorrelated (the “independence model”). That is, it compares the covariance matrix predicted by the model to the observed covariance matrix, and compares the null model (covariance matrix of 0’s) with the observed covariance matrix, to gauge the percent of lack of fit which is accounted for by going from the null model to the researcher’s model.
CFI close to 1 indicates a very good fit. By convention, CFI should be equal to or greater than .90 to accept the model, indicating that 90% of the covariation in the data can be reproduced by the given model.
3. Tucker-Lewis Index (TLI). TLI is similar to CFI, but penalizes for model complexity and is less sensitive to sample size. TLI is not guaranteed to vary from 0 to 1, but if outside the 0 - 1 range it will be arbitrary reset to 0 or 1 (depending on which side of the distribution it falls).
A negative TLI indicates that the chisquare/df ratio for the null model is less than the ratio for the given model, which might occur if one’s given model has very few degrees of freedom and correlations are low. TLI close to 1 indicates a good fit. Rarely, some authors have used the cutoff as low as .80 since TLI tends to run lower than CFI. However, more recently, Hu and Bentler (1999) have suggested TLI > .95 as the cutoff for a good model fit and this is widely accepted. TLI values below .90 indicate a need to respecify the model.
4. Root Mean Square Error of Approximation (RMSEA). RMSEA is the model discrepancy per degree of freedom. By convention, there is good model fit if RMSEA less than or equal to .05. There is adequate fit if RMSEA is less than or equal to .08. RMSEA is a popular measure of fit, partly because it does not require comparison with a null model and thus does not require the author to posit as plausible a model in which there is complete independence of the variables as does, for instance, CFI.
RMSEA has a known distribution, related to the non-central chi-square distribution, and thus does not require bootstrapping to establish confidence intervals. Confidence intervals for RMSEA are reported by R. In a well-fitting model, the lower 90% confidence limit includes or is very close to 0, while the upper limit is less than .08. It is one of the fit indexes less affected by sample size, though for smallest sample sizes it overestimates goodness of fit (Fan, Thompson, and Wang, 1999).
5. Standardized Root Mean Square Residual (SRMR). SRMR is the average difference between the predicted and observed variances and covariances in the model, based on standardized residuals. Standardized residuals are fitted residuals divided by the standard error of the residual. The smaller the SRMR, the better the model fit.
SRMR = 0 indicates perfect fit. A value less than .05 is widely considered good fit and below .08 adequate fit.
6. Warning about interpreting fit indexes. A “good fit” is not the same as strength of relationship. One could have perfect fit when all variables in the model were totally uncorrelated. In fact, the lower the correlations stipulated in the model, the easier it is to find “good fit.” The stronger the correlations, the more power SEM has to detect an incorrect model.
When correlations are low, the researcher may lack the power to reject the model at hand. Also, all measures overestimate goodness of fit for small samples (N < 200), though RMSEA and CFI are less sensitive to sample size than others (Fan, Thompson, and Wang, 1999). In cases where the variables have low correlation, the structural (path) coefficients will be low also. Researchers should report not only goodness-of-fit measures but also the beta coefficients so that the strength of paths in the model can be assessed. Students should not be left with the impression that a model is strong simply because the “fit” is high.
Back to the output
As you can see, because the model is just identified, the fit indexes are perfect. Both CFI and TLI are 1, and RMSEA and RMR are 0. Although little use here, these fit indexes will become very useful late ron as we remove paths from the model.
Also from the summary table we can see that control is a significant predictor of disconnection and disconnection, in turn, is a predictor of exhaustion. The interrelation of these output is EXACTLY the same as linear regression (z is the same as t). This implies that mediation is taking place.
The crucial effect in this analysis, though, is the indirect effect. Here we have an indirect effect (ab) of .07. The interpretation of this estimate is that for every one unit increase in control, there is .07 unit increase on exhaustion passing through disconnection.
The question, however, is: is that .07 effect meaningful? Is that a lot? And is it sufficiently large enough for us to deem a zero indirect effect unlikely? As we saw in last year, to know this we need to bootstrap the sampling distribution of the indirect effect to ascertain the 95% confidence interval. We have the normal theory confidence interval presented in the summary table, but that is no good. We need the bootstrap confidence interval.
To request the bootstrap confidence intervals from the model, we simply pass the model through the parameterestimates() function and stipulate that we want boot.ci.type = “perc”.
Let’s do that now:
parameterestimates(just.model, boot.ci.type = "perc", standardized = TRUE)## lhs op rhs label est se z pvalue ci.lower
## 1 Exhaustion ~ Control c 0.056 0.047 1.198 0.231 -0.025
## 2 Exhaustion ~ Disconnection b 0.181 0.054 3.367 0.001 0.055
## 3 Disconnection ~ Control a 0.359 0.068 5.311 0.000 0.216
## 4 Exhaustion ~~ Exhaustion 0.632 0.052 12.086 0.000 0.513
## 5 Disconnection ~~ Disconnection 1.259 0.101 12.421 0.000 1.053
## 6 Control ~~ Control 1.541 0.000 NA NA 1.541
## 7 ab := a*b ab 0.065 0.023 2.793 0.005 0.018
## 8 total := ab+c total 0.121 0.047 2.571 0.010 0.031
## ci.upper std.lv std.all std.nox
## 1 0.165 0.056 0.084 0.068
## 2 0.294 0.181 0.261 0.261
## 3 0.495 0.359 0.369 0.297
## 4 0.744 0.632 0.908 0.908
## 5 1.461 1.259 0.864 0.864
## 6 1.541 1.541 1.000 1.541
## 7 0.113 0.065 0.096 0.078
## 8 0.232 0.121 0.180 0.145This table outputs two thing that are of most interest:
The standardized estimates, listed under “std.all” and
The bootstrap confidence intervals, listed under “ci.lower” and “ci.upper”
Of most importance here, of course, is the bootstrap confidence interval for the indirect effect. We can see that with 5000 simulations, the 95% confidence interval for our indirect effect of .07 runs from .02 to .12. Crucially, this interval does not include a zero indirect effect and therefore we can reject the null hypothesis. A sense of disconnection with others at work does indeed mediate the relationship between manager control and exhaustion!
Of noting in this table is that double tilda (“~~”) means the residual variances (i.e., error).
Just identified models are just multiple linear regression
As we have seen, just identified models perfectly fit the data because no information is missing. This is how multiple linear regression works, too. When we test models using multiple linear regression, we also have no degrees of freedom - all paths are included (i.e., a, b, and c).
To show that path analysis with a just identified model is exactly the same the multiple linear regression model, we can just rerun the analysis we did last year using lm() and mediation():
## linear model for a path
model.a <- lm(Disconnection ~ 1 + Control, data=data_var)
## linear model for b and c paths
model.b <- lm(Exhaustion ~ 1 + Control + Disconnection, data = data_var)
## mediation analysis using linear regression
mediation <- mediate(model.a, model.b, treat="Control", mediator="Disconnection", boot=TRUE, sims=100, boot.ci.type="perc", conf.level= 0.95) ## Running nonparametric bootstrapsummary(mediation)##
## Causal Mediation Analysis
##
## Nonparametric Bootstrap Confidence Intervals with the Percentile Method
##
## Estimate 95% CI Lower 95% CI Upper p-value
## ACME 0.0648 0.0269 0.11 <2e-16 ***
## ADE 0.0563 -0.0362 0.14 0.22
## Total Effect 0.1211 0.0353 0.22 <2e-16 ***
## Prop. Mediated 0.5350 0.2034 1.69 <2e-16 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Sample Size Used: 212
##
##
## Simulations: 100We can see that the effects in this output are the same as we have from the path modeling approach (give or take rounding differences due to boostrapping). This is no coincidence, a just identified model tested using path analysis is just a fancy way of doing multiple linear regression.
semPaths() can visualize your path models for you, but its a bit clunky and, well, naff:
# unfortunately semPaths plots very small by default, so we set some extra parameters to increase the size to make it readable
semPaths(just.model, "par",
sizeMan = 15, sizeInt = 15, sizeLat = 15,
edge.label.cex=1.5,
fade=FALSE)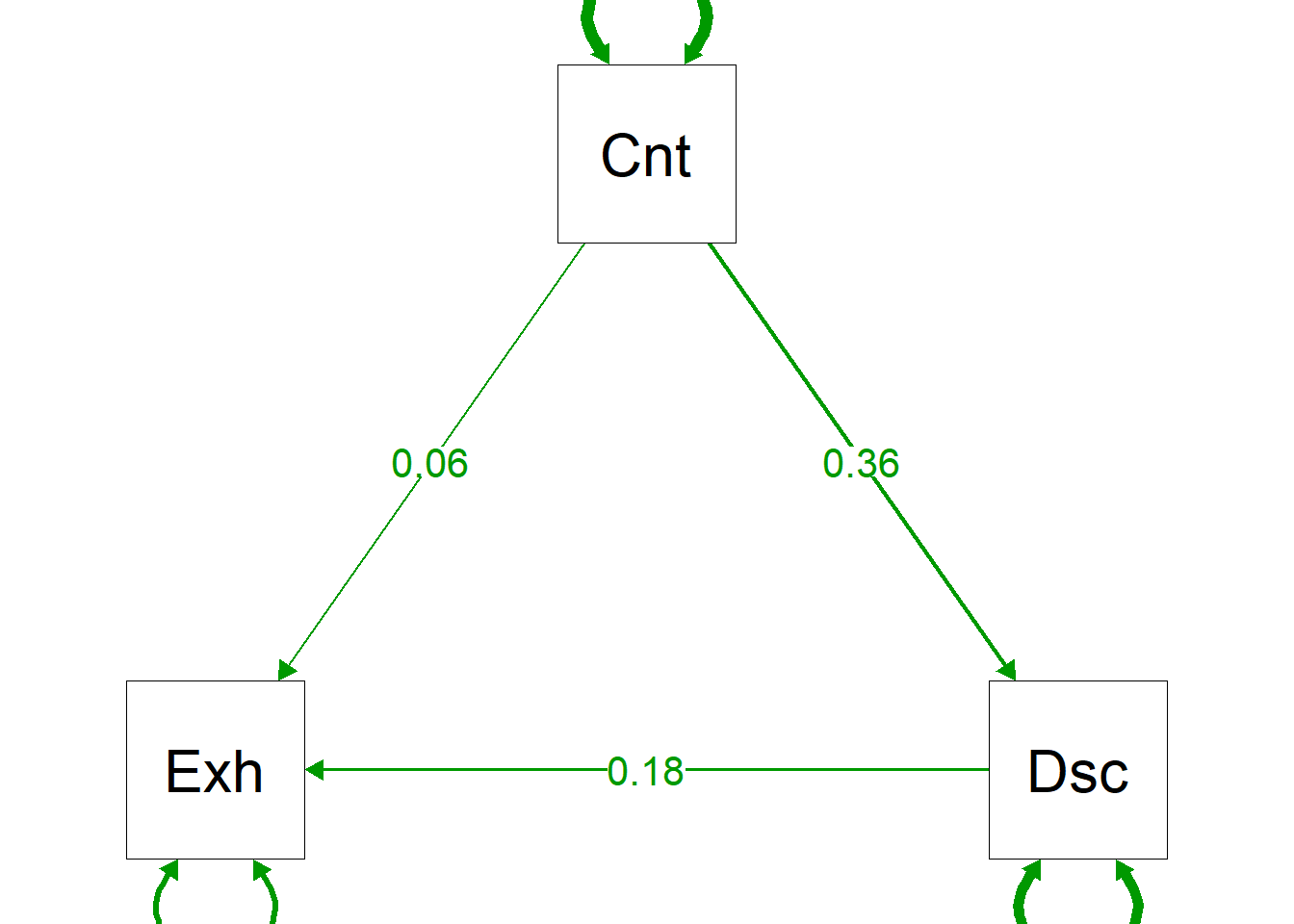
I advise you make your own path model in powerpoint or similar. Something like this:

Much better!
The over identified model
Now, you might be asking: Tom, if the just identified path model is just a fancy way of doing linear regression, then why have you made me do it?!
Well, its because I wanted to show you the real purpose of path analysis. That is, to test over identified models that omit paths and test how well they fit the data.
Recall from the lecture that one of the most important principals of science is parsimony. What if we decided that, actually, we don’t need the direct path (c) in our model. The relationships between the variables are quite adequately represented by the indirect effect only. It is just creating more complexity where none is needed. Theory suggests the c path is not important becuase the effect of control on exhaustion goes fully through disconnection. Let’s grab Occam’s razor and shave it away!

Now we no longer have a just identified model. We have an over identified model because information is missing, namely the c path. Now all we have to go on to compute the correlation matrix is a and b.
If our model is good, and c is not needed, then paths a and b should be sufficient to well-approximate the correlations. But if our model is bad, and c is needed, then a and b alone will not approximate the correlation matrix very well. This is the principal of model fit.
Just as we did for the just identified model, let’s write the code that builds the over identified mediation model, omitting the c path, and save it as object: med.model2.
med.model2 <- "
# the b path
Exhaustion ~ b * Disconnection
# the a path
Disconnection ~ a * Control
# indirect effect
ab := a*b
"And then let’s fit that model:
over.model <- sem(med.model2, data = data_var, se = "bootstrap", bootstrap = 100)Now lets summarize it:
summary(over.model, fit.measures=TRUE, standardized=TRUE, ci=TRUE)## lavaan 0.6-7 ended normally after 13 iterations
##
## Estimator ML
## Optimization method NLMINB
## Number of free parameters 4
##
## Number of observations 212
##
## Model Test User Model:
##
## Test statistic 1.412
## Degrees of freedom 1
## P-value (Chi-square) 0.235
##
## Model Test Baseline Model:
##
## Test statistic 51.347
## Degrees of freedom 3
## P-value 0.000
##
## User Model versus Baseline Model:
##
## Comparative Fit Index (CFI) 0.991
## Tucker-Lewis Index (TLI) 0.974
##
## Loglikelihood and Information Criteria:
##
## Loglikelihood user model (H0) -578.156
## Loglikelihood unrestricted model (H1) -577.450
##
## Akaike (AIC) 1164.311
## Bayesian (BIC) 1177.737
## Sample-size adjusted Bayesian (BIC) 1165.063
##
## Root Mean Square Error of Approximation:
##
## RMSEA 0.044
## 90 Percent confidence interval - lower 0.000
## 90 Percent confidence interval - upper 0.195
## P-value RMSEA <= 0.05 0.350
##
## Standardized Root Mean Square Residual:
##
## SRMR 0.030
##
## Parameter Estimates:
##
## Standard errors Bootstrap
## Number of requested bootstrap draws 100
## Number of successful bootstrap draws 100
##
## Regressions:
## Estimate Std.Err z-value P(>|z|) ci.lower ci.upper
## Exhaustion ~
## Disconnctn (b) 0.202 0.057 3.560 0.000 0.078 0.319
## Disconnection ~
## Control (a) 0.359 0.073 4.881 0.000 0.179 0.484
## Std.lv Std.all
##
## 0.202 0.292
##
## 0.359 0.369
##
## Variances:
## Estimate Std.Err z-value P(>|z|) ci.lower ci.upper
## .Exhaustion 0.636 0.062 10.187 0.000 0.492 0.739
## .Disconnection 1.259 0.103 12.179 0.000 1.055 1.472
## Std.lv Std.all
## 0.636 0.915
## 1.259 0.864
##
## Defined Parameters:
## Estimate Std.Err z-value P(>|z|) ci.lower ci.upper
## ab 0.072 0.025 2.927 0.003 0.026 0.123
## Std.lv Std.all
## 0.072 0.108In this output only paths a and b are tested in the path model. For this reason the b path and the indirect effect (ab) differs slightly to what was estimated in the just identified model.
the lack of a c path also has other implications, namely that it cannot be used to estimate the correlations. So we must make do without it, meaning the model implied correlation matrix will differ from the actual correlation matrix: there will be discrepancy.
And this is why over identified models do not have perfect fit. CFI and TLI are below 1 and RMSEA and SRMR are above 0 The questions is: how far below 1 and above 0 are they?
Recall from the lecture and the information above that there are some rules for the assessment of adequate fit. Methodologies are notorious for disagreeing on these criteria, but there is general agreement that:
TLI and CFI should be above .90 (difference from worst possible fit)
RMSEA and SRMR should be below .10 (difference from perfect fit)
We can see that our model fits the data pretty well based on these criteria. CFI is .99 and the TLI is .97. RMSEA is .04 and SRMR is .03. We say this model fits the data well - the model implied correlation matrix well approximates the actual correlation matrix.
The c path is indeed not needed in the model and this makes sense. Recall for the just identified model that the c path was small and non-significant (b = .06, p > .05). Removing it from the model should have little influence on the estimation of the correlation matrix since its size is small. In the interests of parsimony, then, we should leave it out. It is not needed.
We can compare the matrices directly if we ask for the fitted values for our over identified model. This will output the model implied correlation (or covariance) matirx that can be directly compared to the actual correlation (covariance) matrix of the data. Let’s quickly do that comparison:
## covariance matrix for the data
cov(as.matrix(data_var[,c("Exhaustion","Disconnection", "Control")]))## Exhaustion Disconnection Control
## Exhaustion 0.6991323 0.2958657 0.1875134
## Disconnection 0.2958657 1.4644167 0.5552046
## Control 0.1875134 0.5552046 1.5479349## model implied covariance matrix
fitted(over.model)## $cov
## Exhstn Dscnnc Contrl
## Exhaustion 0.696
## Disconnection 0.294 1.458
## Control 0.112 0.553 1.541As you can see, the covariances are not exactly the same. The model has to estimate the data in the absence of full information. However, crucially, you will see that model pretty well approximates the data. The covariances are closely matched for the pairs of variables (with perhaps the exception of the control-exhaustion pair, which happens to be the path left out). Our model does a pretty good job!
Let’s now quickly call the parameter estimates for the test of that indirect effect:
parameterestimates(over.model, boot.ci.type = "perc", standardized = TRUE)## lhs op rhs label est se z pvalue ci.lower
## 1 Exhaustion ~ Disconnection b 0.202 0.057 3.560 0.000 0.078
## 2 Disconnection ~ Control a 0.359 0.073 4.881 0.000 0.179
## 3 Exhaustion ~~ Exhaustion 0.636 0.062 10.187 0.000 0.492
## 4 Disconnection ~~ Disconnection 1.259 0.103 12.179 0.000 1.055
## 5 Control ~~ Control 1.541 0.000 NA NA 1.541
## 6 ab := a*b ab 0.072 0.025 2.927 0.003 0.026
## ci.upper std.lv std.all std.nox
## 1 0.319 0.202 0.292 0.292
## 2 0.484 0.359 0.369 0.297
## 3 0.739 0.636 0.915 0.915
## 4 1.472 1.259 0.864 0.864
## 5 1.541 1.541 1.000 1.541
## 6 0.123 0.072 0.108 0.087We can see that with 5000 resamples, the 95% confidence interval for our indirect effect of .07 runs from .04 to .13. Again, this interval does not include a zero indirect effect and therefore we can reject the null hypothesis. A sense of disconnection with others at work does indeed mediate the relationship between manager control and exhaustion, even when we leave out the direct effect.
Lastly, it is always a good idea to call the R2 for each of the outcome variables in the model, to ascertain how much variance in our variables is explained by the model. We can do that with the lavInspect() function, requesting “rsquare”.
lavInspect(over.model, what = "rsquare")## Exhaustion Disconnection
## 0.085 0.136We interpret these R2 values just like we always have. About 8% of variance in exhaustion is explained by the path model and about 14% of the variance on disconnection is explained by the path model.
Like before, we can visualize this indirect effect using semPlot. But it is a bit rubbish.
semPaths(over.model, "par",
sizeMan = 15, sizeInt = 15, sizeLat = 15,
edge.label.cex=1.5,
fade=FALSE)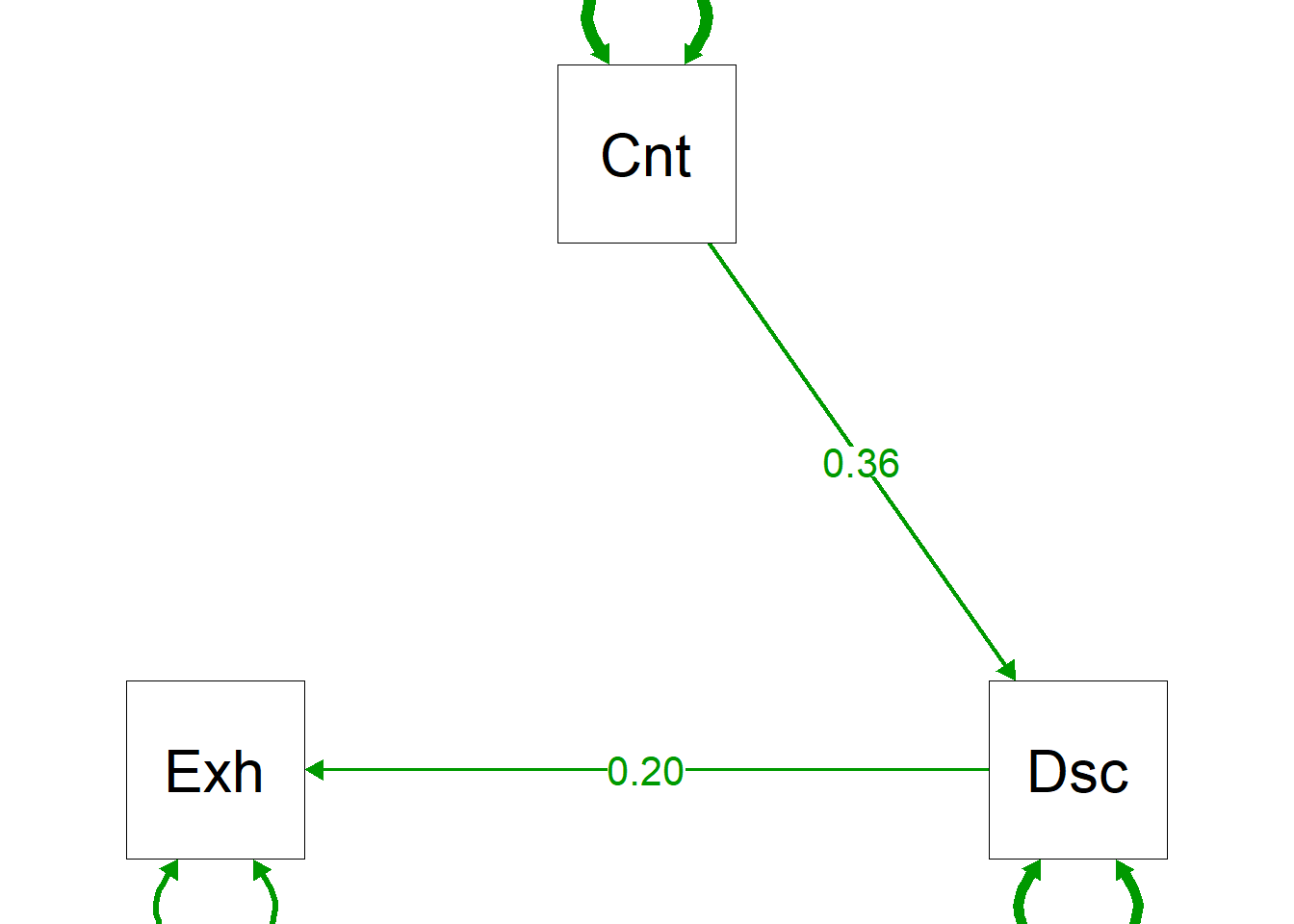
Much better to draw one ourselves:

In addition to the path coefficients and indirect effect, I’ve placed the variance explained (R2) in the top right hand corner of variable box. Looks good!
How its written
In order to test the hypothesized mediation model, path analysis with maximum likelihood estimation was conducted using the laavan R package. A fully mediated model was tested that included one independent variable (manager control), one mediator variable (disconnection), and one dependent variable (exhaustion). Conventional cut-off criteria were adopted to indicate adequate fit for the hypothesised model to the observed data (TLI and CFI > .90, RMSEA and SRMR < .10).
The path model displayed adequate fit to the data (CFI = .99, TLI = .97, RMSEA = .04, SRMR = .03). The path coefficient between manager control and disconnection was significant (b = .36, B = .37, 95% bootstrap CI = .24, 51). Likewise, the path coefficient between disconnection and exhaustion was also significant (b = .20, B = .29, 95% bootstrap CI = .11, .31). To determine whether the mediated effect of manager control on exhaustion through disconnection was statistically significant, the indirect effect (i.e., ab) and its 95% confidence interval was calculated using a bootstrapping procedure that drew 5,000 resamples. The indirect effect was ab = .07 and the bootstrapped confidence interval with 5,000 resamples did not include zero, 95% CI [.04,.13].
Activity: Thirst data
Now it is your turn to have a good at path analysis. We are going to use the thirst data from Table 3.1 in Mackinnon (2008, p. 56). The data frame contains data from 50 students who reported their thirst and water consumption during their lectures. The researchers also measured the room temperature of each lecture at the time the students gave their responses. The researchers hypothesis was that as room temperature increases, people get thirstier, and then they drink more water. In this case, thirst transmits the effect of room temperature on water drinking. Or, in other words,thirst mediates the effect of room temperature on water drinking.
Load the data
Let’s go ahead and load the thirst dataset. You can chaneg the below code or manually load it from the files plane, upto you:
thirst <- read_csv("C:/Users/CURRANT/Dropbox/Work/LSE/PB230/LT2/Workshop/thirst.csv")##
## -- Column specification ---------------------------------------------------------------------
## cols(
## id = col_double(),
## room_temp = col_double(),
## thirst = col_double(),
## consume = col_double()
## )thirst## # A tibble: 50 x 4
## id room_temp thirst consume
## <dbl> <dbl> <dbl> <dbl>
## 1 1 70 4 3
## 2 2 71 4 3
## 3 3 69 1 3
## 4 4 70 1 3
## 5 5 71 3 3
## 6 6 70 4 2
## 7 7 69 3 3
## 8 8 70 5 5
## 9 9 70 4 4
## 10 10 72 5 4
## # ... with 40 more rowsHere we have the core variables of interest: room_temp (x), thirst (m), and consume (y).
Set up the path models
To address the research question and test whether we need the c path, lets run the analysis using both just and over identified models. First, lets set up each model:
# Just identified model
just.thirst.model <- "
# the b and c paths
consume ~ b * thirst + c * room_temp
# the a path
thirst ~ a * room_temp
# indirect effect
ab := a*b
total := ab+c
"
# Over identified model
over.thirst.model <- "
# the b path
consume ~ b * thirst
# the a path
thirst ~ a * room_temp
# indirect effect
ab := a*b
"And then lets fit those models:
# Fit the just identified model
thirst.just.model.fit <- sem(just.thirst.model, data = thirst, se = "bootstrap", bootstrap = 100)
# Fit the over identified model
thirst.over.model.fit <- sem(over.thirst.model, data = thirst, se = "bootstrap", bootstrap = 100)Summarise the just identified model
Now we’ve fit both models. Lets look at the just identified model first. To do this, lets summarize it and request the parameter estimates:
# Summary of just identified model
summary(thirst.just.model.fit, fit.measures=TRUE, standardized=TRUE, ci=TRUE)## lavaan 0.6-7 ended normally after 11 iterations
##
## Estimator ML
## Optimization method NLMINB
## Number of free parameters 5
##
## Number of observations 50
##
## Model Test User Model:
##
## Test statistic 0.000
## Degrees of freedom 0
##
## Model Test Baseline Model:
##
## Test statistic 23.632
## Degrees of freedom 3
## P-value 0.000
##
## User Model versus Baseline Model:
##
## Comparative Fit Index (CFI) 1.000
## Tucker-Lewis Index (TLI) 1.000
##
## Loglikelihood and Information Criteria:
##
## Loglikelihood user model (H0) -137.275
## Loglikelihood unrestricted model (H1) -137.275
##
## Akaike (AIC) 284.550
## Bayesian (BIC) 294.110
## Sample-size adjusted Bayesian (BIC) 278.416
##
## Root Mean Square Error of Approximation:
##
## RMSEA 0.000
## 90 Percent confidence interval - lower 0.000
## 90 Percent confidence interval - upper 0.000
## P-value RMSEA <= 0.05 NA
##
## Standardized Root Mean Square Residual:
##
## SRMR 0.000
##
## Parameter Estimates:
##
## Standard errors Bootstrap
## Number of requested bootstrap draws 100
## Number of successful bootstrap draws 100
##
## Regressions:
## Estimate Std.Err z-value P(>|z|) ci.lower ci.upper
## consume ~
## thirst (b) 0.451 0.137 3.293 0.001 0.179 0.788
## room_temp (c) 0.208 0.114 1.827 0.068 -0.019 0.426
## thirst ~
## room_temp (a) 0.339 0.104 3.259 0.001 0.081 0.552
## Std.lv Std.all
##
## 0.451 0.413
## 0.208 0.208
##
## 0.339 0.371
##
## Variances:
## Estimate Std.Err z-value P(>|z|) ci.lower ci.upper
## .consume 0.912 0.160 5.698 0.000 0.522 1.165
## .thirst 0.911 0.176 5.168 0.000 0.581 1.291
## Std.lv Std.all
## 0.912 0.723
## 0.911 0.862
##
## Defined Parameters:
## Estimate Std.Err z-value P(>|z|) ci.lower ci.upper
## ab 0.153 0.063 2.408 0.016 0.040 0.325
## total 0.360 0.102 3.546 0.000 0.158 0.566
## Std.lv Std.all
## 0.153 0.153
## 0.360 0.361# Parameter estimates of just identified model
parameterestimates(thirst.just.model.fit, boot.ci.type = "perc", standardized = TRUE)## lhs op rhs label est se z pvalue ci.lower ci.upper
## 1 consume ~ thirst b 0.451 0.137 3.293 0.001 0.179 0.788
## 2 consume ~ room_temp c 0.208 0.114 1.827 0.068 -0.019 0.426
## 3 thirst ~ room_temp a 0.339 0.104 3.259 0.001 0.081 0.552
## 4 consume ~~ consume 0.912 0.160 5.698 0.000 0.522 1.165
## 5 thirst ~~ thirst 0.911 0.176 5.168 0.000 0.581 1.291
## 6 room_temp ~~ room_temp 1.268 0.000 NA NA 1.268 1.268
## 7 ab := a*b ab 0.153 0.063 2.408 0.016 0.040 0.325
## 8 total := ab+c total 0.360 0.102 3.546 0.000 0.158 0.566
## std.lv std.all std.nox
## 1 0.451 0.413 0.413
## 2 0.208 0.208 0.185
## 3 0.339 0.371 0.329
## 4 0.912 0.723 0.723
## 5 0.911 0.862 0.862
## 6 1.268 1.000 1.268
## 7 0.153 0.153 0.136
## 8 0.360 0.361 0.321We know the fit of the just identified model is perfect, so we don’t need to inspect the fit indexes. But we do need to look at the estimates.
What is the a path and is it significant?
What is the b path and is it significant?
What is the ab path and is it significant?
What can we say in relation to the study hypothesis?
Summarise the over identified model
Lets now summarise and request the parameter estimates for the over identified model.
# Summary of over identified model
summary(thirst.over.model.fit, fit.measures=TRUE, standardized=TRUE, ci=TRUE)## lavaan 0.6-7 ended normally after 10 iterations
##
## Estimator ML
## Optimization method NLMINB
## Number of free parameters 4
##
## Number of observations 50
##
## Model Test User Model:
##
## Test statistic 2.519
## Degrees of freedom 1
## P-value (Chi-square) 0.113
##
## Model Test Baseline Model:
##
## Test statistic 23.632
## Degrees of freedom 3
## P-value 0.000
##
## User Model versus Baseline Model:
##
## Comparative Fit Index (CFI) 0.926
## Tucker-Lewis Index (TLI) 0.779
##
## Loglikelihood and Information Criteria:
##
## Loglikelihood user model (H0) -138.534
## Loglikelihood unrestricted model (H1) -137.275
##
## Akaike (AIC) 285.068
## Bayesian (BIC) 292.716
## Sample-size adjusted Bayesian (BIC) 280.161
##
## Root Mean Square Error of Approximation:
##
## RMSEA 0.174
## 90 Percent confidence interval - lower 0.000
## 90 Percent confidence interval - upper 0.457
## P-value RMSEA <= 0.05 0.135
##
## Standardized Root Mean Square Residual:
##
## SRMR 0.073
##
## Parameter Estimates:
##
## Standard errors Bootstrap
## Number of requested bootstrap draws 100
## Number of successful bootstrap draws 100
##
## Regressions:
## Estimate Std.Err z-value P(>|z|) ci.lower ci.upper
## consume ~
## thirst (b) 0.535 0.132 4.057 0.000 0.296 0.826
## thirst ~
## room_temp (a) 0.339 0.111 3.055 0.002 0.089 0.545
## Std.lv Std.all
##
## 0.535 0.490
##
## 0.339 0.371
##
## Variances:
## Estimate Std.Err z-value P(>|z|) ci.lower ci.upper
## .consume 0.960 0.164 5.853 0.000 0.616 1.228
## .thirst 0.911 0.139 6.537 0.000 0.622 1.157
## Std.lv Std.all
## 0.960 0.760
## 0.911 0.862
##
## Defined Parameters:
## Estimate Std.Err z-value P(>|z|) ci.lower ci.upper
## ab 0.181 0.076 2.380 0.017 0.052 0.324
## Std.lv Std.all
## 0.181 0.182# Parameter estimates of over identified model
parameterestimates(thirst.over.model.fit, boot.ci.type = "perc", standardized = TRUE)## lhs op rhs label est se z pvalue ci.lower ci.upper
## 1 consume ~ thirst b 0.535 0.132 4.057 0.000 0.296 0.826
## 2 thirst ~ room_temp a 0.339 0.111 3.055 0.002 0.089 0.545
## 3 consume ~~ consume 0.960 0.164 5.853 0.000 0.616 1.228
## 4 thirst ~~ thirst 0.911 0.139 6.537 0.000 0.622 1.157
## 5 room_temp ~~ room_temp 1.268 0.000 NA NA 1.268 1.268
## 6 ab := a*b ab 0.181 0.076 2.380 0.017 0.052 0.324
## std.lv std.all std.nox
## 1 0.535 0.490 0.490
## 2 0.339 0.371 0.329
## 3 0.960 0.760 0.760
## 4 0.911 0.862 0.862
## 5 1.268 1.000 1.268
## 6 0.181 0.182 0.161Because the model is over identified we have fit indexes to inspect
What is the CFI and is is adequate?
What is the TLI and is it adequate?
What is the RMSEA and is it adequate?
What is the SRMR and is it adequate?
If the fit is not adequate what does this mean?
Which model should we prefer, the just identified model or the over identified model?