Factorial ANOVA (LT5)
To this point in the course, we have looked at the linear model as an underlying framework for statistical analysis and we applied this to comparing groups and examining relationships. Since then, we’ve focussed on regression and the building block of linear models that have multiple predictor variables used to explain a single outcome variable. The goal this week is to extend these ideas into the analysis of experimental data containing multiple grouping (categorical) variables on a single outcome variable. The tool for doing so is generically referred to as factorial ANOVA but, as we will see, it follows the same principals of the linear model.
Learning Outcomes
By the end of this workshop, you should be able to:
Run a between-persons ANOVA with and without interactions
Run a within-persons ANOVA
Understand how to run a mixed ANOVA
Install required packages
install.packages("probemod")
install.packages("tidyverse")
install.packages("ggplot2")
install.packages("fastDummies")
install.packages("car")
install.packages("sjstats")
install.packages("supernova")
install.packages("data.table")
install.packages("emmeans")
install.packages("psych")Load required packages
The required packages are the same as the installed packages. Write the code needed to load the required packages in the below R chunk.
library(probemod)
library(tidyverse)
library(ggplot2)
library(fastDummies)
library(car)
library(supernova)
library(sjstats)
library(data.table)
library(emmeans)
library(psych)2 x 2 between-subjects factorial ANOVA with no interaction using the linear model
Let's first look at a between-subjects 2 x 2 Factorial ANONA in which the predictor variables are both categorical with 2 categories (i.e., 2 x 2 design).
The data
To demonstrate a 2 x 2 between-subjects ANOVA we are going to use the student data from the Navarro reading. Here, a researcher was inerested to know whether students obtained higher grades if they attended class (varibale name attend in dataset) and did the readings (variable name reading in the dataset). In this dataset, the predictor variabes - class attendance and readings - were coded as categorical variables with two levels; yes or no. I have created two separate datasets for this task - rtfm.1 and rtfm.2 - both of which are contained in the rtfm.Rdata file. In rtfm.1, the predictors are numerically coded 1 (yes) and 0 (no) for lm() and in the rtfm.2 they are coded categorically (i.e., "yes" and "no") for aov(). Grades is continuous variable of GPA scores.
Lets load the rtfm.rdata file into our R studio session. To do so, find the rtfm.Rdata file in the LT5 workshop folder, click on it, and then click yes to load it into the global environment. Altenratively, you might be able to run the code below (if neither of these methods work, put your hand up)
load("C:/Users/tc560/Dropbox/Work/LSE/PB130/LT5/Workshop/rtfm.Rdata")When you load this file you will find two data objects in the environment; rtfm.1 and rtfm.2. The details for these files are listed above. First, we are going to use the rtfm.1 dataframe to conduct the 2x2 ANOVA with the linear model and then we will see the equivalence of the linear model with aov() using the rtfm.2 dataframe. As we saw in the lecture, ANOVA is just a special case of the linear model.
As always, before we delve into this topic lets just clarify the research question and null hypothesis we are testing:
Research Question 1 - Is there a significant difference in grades between students who attended class and students who did not attend class?
Research Question 2 - Is there a significant difference in grades between students who did the reading and students who did not do the reading?
Null Hypothesis 1 - The grade difference between students who attended class and students who did not attend class will be zero.
Null Hypothesis 2 - The grade difference between students who did the reading and students who did not do the reading will be zero.
Setting up the linear model
Now lets set our up our linear model to test our null hypotheses. For this, we just use the linear model, but rather than enter two continuous predictor variables, as we have been doing for multiple regression, we add two categorical predictor variables. The nauture of the variables (i.e., categorical) is what differentiates ANOVA from regression - but that is all! Otherwise, the underlying test is exactly the same.
Becuase of this difference, the lm() function only takes numerical input whereas the aov() only takes categorical input. There are other advantages of using the aov() function for ANOVA that I will come to, but what I want to show you right now is that ANOVA is just a linear model with categorical variables.
To build our linear model, then, we are going to use the rtfm.1 dataset that codes the predictor variables numerically (i.e., 0 and 1). And we are going to write the lm() jsut as we have for multiple regression by adding each predictor to the model with a "+". Notationally, this model can be expresses in the GLM as:
Yi = b0 + b1Xi + b2Xi + ei
Exactly the same as the multiple re gression equation from LT2. ANOVA is just a linear model. Let's go ahead that build that model now and save it as a new R object called "linear.model1".
linear.model1 <- lm (grade ~ 1 + attend + reading, data = rtfm.1)
summary(linear.model1)##
## Call:
## lm(formula = grade ~ 1 + attend + reading, data = rtfm.1)
##
## Residuals:
## 1 2 3 4 5 6 7 8
## 0.5 -2.5 3.5 -1.5 -8.5 6.5 3.5 -1.5
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 43.500 3.354 12.969 4.86e-05 ***
## attend 18.000 3.873 4.648 0.00559 **
## reading 28.000 3.873 7.230 0.00079 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 5.477 on 5 degrees of freedom
## Multiple R-squared: 0.9366, Adjusted R-squared: 0.9112
## F-statistic: 36.93 on 2 and 5 DF, p-value: 0.001012The interpretation of this output is exactly the same as we have been working with for group comparisons and relationships. The intercept is the mean grade for students who did not attend class (attend = 0) and did not do the readings (reading = 0). The slope estimate for attend is the boost needed to the intercept to get to the mean grade for students who attened class (attend = 1) but did not do the readings (reading = 0). The slope estimate for reading is the boost needed to the intercept to get the mean grade for students who did not attend class (class = 0) but did do the readings (readings = 1).
As you can see, just like in multiple regression these slopes are unique effects. That is, the effect of class attendance on grades, controlling for reading, and the effect of reading on grades, controlling for class attendance. If we were to run two separte linear models for attendance and reading, we would not be controlling for their shared effects. Given this, it is evident that while both appear important to grades, reading is an especially strong predictor.
Both slope estimates are statistically significant, with p values < .05. We can further test statistical significance by calculating the 95% bootstrap confidence intervals around these estimates.
lm.model1.boot <- Boot(linear.model1, f=coef, R = 5000)
confint(lm.model1.boot, level = .95, type = "norm")## Bootstrap normal confidence intervals
##
## 2.5 % 97.5 %
## (Intercept) 34.52474 52.52294
## attend 10.28419 25.50556
## reading 20.49070 35.54599The confidence intervals for each slope estimate do not include zero. We can reject the null hypothesis. It appears that both class attendance and reading significantly boost grades!
Partitioning variance
We've established whether there is a statistically significant relationship, but how much variance in grades is explained by a combination of class attendance and reading and how is this overall variance explianed is partitioned between the two predictors? We can answer this question using the supernova() function in R, which breaks down the variance in grades due to the overall model (ie., a combination of attendance and reading), the model predictors (i.e., attendance and reading separately) and error (i.e., variance left over once we've subtracted out the linear model).
supernova(linear.model1)## Analysis of Variance Table (Type III SS)
## Model: grade ~ 1 + attend + reading
##
## SS df MS F PRE p
## ------- --------------- | -------- - -------- ------ ------ -----
## Model (error reduced) | 2216.000 2 1108.000 36.933 0.9366 .0010
## attend | 648.000 1 648.000 21.600 0.8120 .0056
## reading | 1568.000 1 1568.000 52.267 0.9127 .0008
## Error (from model) | 150.000 5 30.000
## ------- --------------- | -------- - -------- ------ ------ -----
## Total (empty model) | 2366.000 7 338.000As we know by now, the supernova table shows us that the sum of squares for the empty model of grades is 2366.00. Adding reading and class attendance to the linear model of grades has minimised the error in the empty model by 2216.00 sum of squares. Is this alot? Certainly looks like it! Furthermore, the PRE or R2 is .94 and so 94% of grade variance is explained by class attendance and reading. The F ratio, which is the ratio of the mean square for the model to the mean square for the error left over after subtracting out the model, is large and stastically significant (i.e., p < .05). Our linear model is indeed a much better model than the empty model.
In this table is also the variance explained in grades by each each predictor. We can see that of the 2366 sum of squares in the empty model, 648 is reduced by class attendance and 1568 by reading. As we will see, these are sometimes called main effects in ANOVA - and are tested with their respective F-ratios. Alongside the F ratio, each predictor has a PRE or R2 for their respective main effect. This metric is an effect size, often reported as partial eta-squared (pη2) and tells us how large the overall effect is for a particular predictor. Cohen (1988) has provided benchmarks to define small (pη2 = 0.01), medium (pη2 = 0.06), and large (pη2 = 0.14) effects. These are very large effects! As well, supporting the slope estimates in the linear model, both of the main effects are statistically significant.
We can, therefore, reject the null hypotheses and conclude that student grades are higher among students who do the readings and attend the classes.
Equivalence with aov()
Now, traditionally, 2 x 2 ANOVA is tested using the dedicated aov() function that takes categorical input. By doing this, students are led to wrongly believe that in some way ANOVA and regression are seperate analyses when, in fact, they are doing exactly the same thing. To demonstrate this, lets build the same linear model of grades using the aov() function and save it as a new R object called "anova.model1". The aov() function takes categorical not numerical input for the predictors and therefore we need to use the rtfm.2 dataframe.
anova.model1 <- aov(grade ~ attend + reading, data = rtfm.2)
summary(anova.model1)## Df Sum Sq Mean Sq F value Pr(>F)
## attend 1 648 648 21.60 0.00559 **
## reading 1 1568 1568 52.27 0.00079 ***
## Residuals 5 150 30
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1eta_sq(anova.model1, partial=TRUE)## Warning: 'eta_sq' is deprecated.
## Use 'effectsize::eta_squared()' instead.
## See help("Deprecated")## Parameter | Eta2 (partial) | 90% CI
## -----------------------------------------
## attend | 0.81 | [0.35, 0.92]
## reading | 0.91 | [0.65, 0.96]The output presents the two main effects for each of attendance and reading on grades as well as the effect sizes (partial eta squared). And what do you know, these main effects and effect sizes are EXACTLY the same as those outputted in the supernova table above. Go ahead and check them. I suggested earlier that there are some benefits of using the dedicated aov() function rather than lm() to test linear models with categorial predictors (i.e., factorial ANOVA) and this is becuase they allow us to make direct comparisons of the means. The supernova output reports whats called an omnibus F test for the main effects that tests the null hypothesis that there is no significant difference across the groups within the predictor variable. Obtaining a significant F for the omnibus test doesn't tell you which groups are different to which. We can use the linear model to calculate these differences with the slope coefficients and with 2 predictors each containing 2 levels this is quite straightforward. Indeed, we did this when we inspected the intercept and slope coefficients from the linear.model1 above.
Post-hoc testing
However, as the number of categories per predictor increases, comparing the means becomes alot more complicated becuase of the sheer number of group comparisons. Within the factoral anova model, just like the one-way ANOVA model, we can conduct post-hoc analyses that examine all possible group comparisons being tested using something called pairwise differences. These kinds of comparisons are often called simple effects, apparently referring to the fact they are just comparing means in a straight forward way. To give you an example of this, in the anonva.model1 there are two specific mean comparisons are being tested:
The difference in grades between those who attended class and those who did not
The difference in grades between those who did the readings and those who did not
A tool called Tukey's "Honestly Significant Difference" (or Tukey's HSD for short) makes these comparisons from the factoral ANOVA model. It constructs 95% simulataneous confidence intervals around each specific mean comparison. Simultaneous just means that there is a 95% probability all of these confidence intervals including the true difference in the population. To all intents and purposes, it is interpreted in the same way we have been interpreting 95% confidence intervals to date. Lets go ahead and request Tukey's HSD using the TukeyHSD() function from the anova.model1 object.
TukeyHSD(anova.model1)## Tukey multiple comparisons of means
## 95% family-wise confidence level
##
## Fit: aov(formula = grade ~ attend + reading, data = rtfm.2)
##
## $attend
## diff lwr upr p adj
## yes-no 18 8.04418 27.95582 0.0055943
##
## $reading
## diff lwr upr p adj
## yes-no 28 18.04418 37.95582 0.0007899As we can see, this analysis has outputted those two mean comparisons for us. One for attendance and one for reading. And, just to further demonstrate the equivalence of ANOVA and regression, go ahead and look at the slope coefficients from the linear model above. They are exactly the same as these mean comparisons (i.e., 18 and 28). We can also see that the 95% confidence intervals do not cross zero for each comparison and this therefore supports our earlier conclusions that there are mean differences in grades across the two groups.
For a simple 2 x 2 ANOVA, the mean comparisons are a striaghtforward replication of the slope coeffcients for each caegorical predictor. However, as the number of levels in the categorical predictor increase, examination of the pairwise comparions becomes very useful to researchers, as we shall see in the 2 x 3 ANOVA.
2 x 2 between-subjects factorial ANOVA with interaction as a linear model
Now lets look at a 2 x 2 between-subjects factorial ANONA with an interaction in the same student dataset. Whereas in the first example we just looked at main effects of reading and attendance, this time we'll look at main and interactive effects in the same model. You won't be surprised to learn that this is really just an extention of what we did in LT3 when we tested moderation - but, of course, with two categorical predictors rather than two continuous predictors. Buts thats the only difference! Factoral ANOVA is just regression with categorical variables. And when we add an interaction term to the model, we are simply doing exactly what we did in LT3 - adding an interaction term to the linear model notation:
Y = b0 + b1X + b2m + b3xm
Recognise that formula? Its exactly the same as the regression formula for moderation analysis, but in this case the x and m variables are categorical and we are hypothesising that these categorical predictors interact in some way to explain variance in the outcome. Of interest here is the reading by attendance interaction, and we are presupposing that reading and attendance have some kind of synergistic relationship. That is, they each have their own contribution to grades as we saw above, but they also interact in some way to impact grades.
As always, before we delve into this topic lets just clarify the research question and null hypothesis we are testing:
Research Question - Is the effect of attendance on grades moderated by reading?
Null Hypothesis - The interaction of attendance and reading on grades will be zero.
Setting up the linear model
Lets set up the linear model. And we don't need to intoduce anything new here - we are just building a moderated regression model in the same way as we did in LT3 - but this time we are using categorical predictors rather than continuous. For this, we just add the interaction term to the main effects linear model we built above (linear.model1). So lets do that now and create a new R object called "linear.model2"
linear.model2 <- lm(grade ~ 1 + attend + reading + attend*reading, data=rtfm.1) # notice that all I am doing here is adding the interaction term to the linear model
summary(linear.model2)##
## Call:
## lm(formula = grade ~ 1 + attend + reading + attend * reading,
## data = rtfm.1)
##
## Residuals:
## 1 2 3 4 5 6 7 8
## 1.5 -1.5 2.5 -2.5 -7.5 7.5 2.5 -2.5
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 42.500 4.213 10.088 0.000543 ***
## attend 20.000 5.958 3.357 0.028391 *
## reading 30.000 5.958 5.035 0.007307 **
## attend:reading -4.000 8.426 -0.475 0.659748
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 5.958 on 4 degrees of freedom
## Multiple R-squared: 0.94, Adjusted R-squared: 0.895
## F-statistic: 20.88 on 3 and 4 DF, p-value: 0.006617We already know that in a linear model with an interaction term, the estimates for b1 and b2 become conditional effects. So here the intercept estimate is the mean grade for students who did not attend class (coded 0) and did not do the readings (coded 0). The slope for attendance is the boost needed to the intercept to find the mean grade for students who did attend (coded 1) but did not do the readings (coded 0). The slope for reading is the boost needed to the intercept to find the mean grade for students who did the reading (coded 1) but did not attend class (coded 0).
As we know from LT3, these main effects, as we have been calling them, are irrelevant in the presence of a significant interaction term because they will depend on the level of the moderator. In this case, however, the interaction of reading and attendance is not significant, and this means that the effect of attendance on grades does not depend on whether students did the reading (and vice versa) - the effect is independent of, or not conditional upon, reading. We can further test statistical significance by calculating the 95% bootstrap confidence intervals around these estimates.
lm.model2.boot <- Boot(linear.model2, f=coef, R = 5000)
confint(lm.model2.boot, level = .95, type = "norm")## Bootstrap normal confidence intervals
##
## 2.5 % 97.5 %
## (Intercept) 30.706262 54.029381
## attend 7.810409 32.408605
## reading 17.875887 42.357030
## attend:reading -17.187731 9.005804As with the normal theory estimates, the confidence interval for the interaction estimate includes zero. We should accept the null hypothesis.
Equivalence with aov()
As with the example above, all we have done is test a linear model with an ineraction term. Doing the same analysis with aov() tests exactly the same model - but with categorical input. To demonstrate this, lets build the same moderated linear model of grades using the aov() function and save it as a new R object called "anova.model2". The aov() function takes categorical not numerical input for the predictors and therefore we need to use the rtfm.2 dataframe.
anova.model2 <- aov(grade ~ 1 + attend + reading + attend*reading, data = rtfm.2)
summary(anova.model2)## Df Sum Sq Mean Sq F value Pr(>F)
## attend 1 648 648.0 18.254 0.01293 *
## reading 1 1568 1568.0 44.169 0.00266 **
## attend:reading 1 8 8.0 0.225 0.65975
## Residuals 4 142 35.5
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1supernova(linear.model2)## Analysis of Variance Table (Type III SS)
## Model: grade ~ 1 + attend + reading + attend * reading
##
## SS df MS F PRE p
## -------------- --------------- | -------- - ------- ------ ------ -----
## Model (error reduced) | 2224.000 3 741.333 20.883 0.9400 .0066
## attend | 400.000 1 400.000 11.268 0.7380 .0284
## reading | 900.000 1 900.000 25.352 0.8637 .0073
## attend:reading | 8.000 1 8.000 0.225 0.0533 .6597
## Error (from model) | 142.000 4 35.500
## -------------- --------------- | -------- - ------- ------ ------ -----
## Total (empty model) | 2366.000 7 338.000The output presents the two main effects for each of attendance and reading on grades and their interaction term. Ignore the SS and MS for the main effects - with an itneraction term in the model, these effects depend on how the variables are coded and that is why they differ from the linear model output (aov codes differently to 0, 1). If you think back to the moderation lecture, I showed you what happens to the slope coefficients when the scale of measurement changes (i.e., mean centering). That is exactly what is happening here - aov() codes the variables differently to 0,1 and, therefore, the main effects differ across the models. Instead, I want you to focus on the SS, MS, and p value for the interaction term because we know this stays the same irrespective of how the predictor vairables are coded. And what do you know, this term has exactly the same SS, MS, and p value in the ANOVA model as in the linear model. Go ahead and check them.
2 x 3 between-subjects factoral ANOVA with interaction as linear model
Let's now look at a 2 x 3 between-subjects factoral ANONA in which one predictor variable has 2 categories and one has 3 (i.e., 2 x 3 design).
The data
To demonstrate a 2 x 3 between-subjects factoral ANOVA we are going to use the clinical trial data from the Navarro reading. Here, a researcher was inerested to know whether patients attending a 2 week Cognitive Behavioural Therapy (CBT) intervention showed better gain in their mood (variable mood.gain) than those who did not receive CBT over the same period. The researcher was also interested in whether any differences in mood were moderated by the type of antidepressant drug the patients were taking (variable drug). Here, there we 3 categories of drugs, namely anxifree, joyzepam, and placebo. In this dataset, the predictor variabes - therapy and drug - were coded as categorical variables. Therapy has 2 levels (CBT and no therapy) and drug has 3 levels (anxifree, joyzepam, and placebo). This is a classic 2 x 3 factoral ANOVA design with a interaction.
I have created one dataset for this task - clin.trial - which is contained in the clinicaltrial.Rdata file. In clin.trial, the predictors are categorically and mood.gain is a continuous numeric outcome .
Lets load the clinicaltrial.rdata file into our R studio session. To do so, find the rtfm.Rdata file in the LT5 workshop folder, click on it, and then click yes to load it into the global environment. Altenratively, you might be able to run the code below (if neither of these methods work, put your hand up)
load("C:/Users/tc560/Dropbox/Work/LSE/PB130/LT5/Workshop/clinicaltrial.Rdata")The model we are testing for the 2 x 3 between-subjects factoral ANOVA is exactly the same as the 2 x 2 between-subjects factoral ANOVA above except that one of the factors has 2 groups (therapy) and one has 3 groups (drug). The aim here is to compare the means within the groups (i.e., main effects of therapy and drug on mood gain) plus these group means multiplied across the factors (interaction effects). As we have just seen, the main effects are exactly the same as one-way ANOVAs that we tested in LT9, though in the context of a larger model that tests unique effects (i.e., 2 predictors rather than 1 predictor). The interaction effect in a 2 x 3 factoral ANOVA is a little harder to explain in the abstract than the 2 x 2 model, but stick with me because its really just a few numbers multiplied with each other.
Recall in LT9 that when we have a predictor with 3 levels, like our drug variable, we need to create 2 dummy variables. In our example, we create one dummy variable that contrasts joyzepam with others and one dummy variable that contrasts anxifree with others. Set up this way, placebo is the reference group. We do not need to do anything with the therapy factor as it has 2 levels, but we will also numerically dummy code it for the linear model.
We could dummy code the variables by hand, but there is a useful function in R that does this for us. Its called fastdummies and uses a dummy_cols() function to dummy code variables given a categorical input. So lets go ahead and create those dummy variables.
clin.trial <- dummy_cols(clin.trial, select_columns = "drug")
clin.trial <- dummy_cols(clin.trial, select_columns = "therapy") # into the perfectionism dataframe create dummy columns using the "Country" variable in the perfectionism data frame
clin.trial## drug therapy mood.gain drug_placebo drug_anxifree drug_joyzepam
## 1 placebo no.therapy 0.5 1 0 0
## 2 placebo no.therapy 0.3 1 0 0
## 3 placebo no.therapy 0.1 1 0 0
## 4 anxifree no.therapy 0.6 0 1 0
## 5 anxifree no.therapy 0.4 0 1 0
## 6 anxifree no.therapy 0.2 0 1 0
## 7 joyzepam no.therapy 1.4 0 0 1
## 8 joyzepam no.therapy 1.7 0 0 1
## 9 joyzepam no.therapy 1.3 0 0 1
## 10 placebo CBT 0.6 1 0 0
## 11 placebo CBT 0.9 1 0 0
## 12 placebo CBT 0.3 1 0 0
## 13 anxifree CBT 1.1 0 1 0
## 14 anxifree CBT 0.8 0 1 0
## 15 anxifree CBT 1.2 0 1 0
## 16 joyzepam CBT 1.8 0 0 1
## 17 joyzepam CBT 1.3 0 0 1
## 18 joyzepam CBT 1.4 0 0 1
## therapy_no.therapy therapy_CBT
## 1 1 0
## 2 1 0
## 3 1 0
## 4 1 0
## 5 1 0
## 6 1 0
## 7 1 0
## 8 1 0
## 9 1 0
## 10 0 1
## 11 0 1
## 12 0 1
## 13 0 1
## 14 0 1
## 15 0 1
## 16 0 1
## 17 0 1
## 18 0 1Now we have our numeric dummy variables for the linear model, lets take a peek at what a 2 x 3 factoral ANOVA looks like in notational form:
Y = b0 + b1X + b2m1 + b3m2 + b4xm1 + b5xm2
Notice here that the formula is a little more elaborated than a 2 x 2 ANOVA above. This is because the second factor (drug) has 3 levels and therefore needs to be captured with 2 dummy variables (m1 and m2). This also necessitates two interactions, one between x and m1 and one between x and m2. But thats it, thats the only difference between notation for the 2 x 2 and 2 x 3 ANOVA. With an itneraction in the model, of course, the interaction terms become the focal coeffcients of interest. We should know that by now! And as more levels are added to the categorical preditor(s), the number of dummy variables and therefore interactions also increases. It is for this reason that aov() should be prefered in factoral ANOVA analyses - but the point I want you to take away is that aov() is just a linear model under the bonnet.
As always, before we delve into this topic lets just clarify the research question and null hypothesis we are testing:
Research Question - Is the effect of therapy on mood moderated by drug?
Null Hypothesis - The interaction of therapy and drug on mood will be zero.
Setting up the linear model
Lets set up the linear model. And we don't need to intoduce anything new here - we are just building a linear model in the same way as we did for the 2 x 2 between-subjects factoral ANOVA - but this time we have have a predictor with 3 levels rather than 2. For this, we just add the relevant dummy variables and interaction terms from the GLM formula above. So lets do that now and create a new R object called "linear.model2full".
linear.model3full <- lm(mood.gain ~ 1 + therapy_CBT + drug_anxifree + drug_joyzepam + therapy_CBT*drug_anxifree + therapy_CBT*drug_joyzepam, data=clin.trial)
summary(linear.model3full)##
## Call:
## lm(formula = mood.gain ~ 1 + therapy_CBT + drug_anxifree + drug_joyzepam +
## therapy_CBT * drug_anxifree + therapy_CBT * drug_joyzepam,
## data = clin.trial)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.3000 -0.1917 0.0000 0.1917 0.3000
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 0.3000 0.1347 2.227 0.0459 *
## therapy_CBT 0.3000 0.1905 1.575 0.1413
## drug_anxifree 0.1000 0.1905 0.525 0.6092
## drug_joyzepam 1.1667 0.1905 6.124 5.15e-05 ***
## therapy_CBT:drug_anxifree 0.3333 0.2694 1.237 0.2397
## therapy_CBT:drug_joyzepam -0.2667 0.2694 -0.990 0.3418
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.2333 on 12 degrees of freedom
## Multiple R-squared: 0.8652, Adjusted R-squared: 0.809
## F-statistic: 15.4 on 5 and 12 DF, p-value: 7.334e-05We already know that, in a linear model with interaction terms, the estimates for the main effects become conditional effects. As the number of interaction terms increase, the interpretation of the main effects become more complex so we won't dwell on them here. In any case, the focal coeffients are the interactions. And we can see here that the interaction terms are not significant, and this means that the effects of therapy on mood does not depend on what drug the patients are taking - the effect is independent of, or not conditional upon, drug. We can further test statistical significance by calculating the 95% bootstrap confidence intervals around these estimates.
lm.model3.boot <- Boot(linear.model3full, f=coef, R = 5000)
confint(lm.model3.boot, level = .95, type = "norm")## Bootstrap normal confidence intervals
##
## 2.5 % 97.5 %
## (Intercept) 0.08471830 0.5142391
## therapy_CBT -0.08573941 0.6897638
## drug_anxifree -0.19951770 0.4016418
## drug_joyzepam 0.85699170 1.4754076
## therapy_CBT:drug_anxifree -0.16100390 0.8238559
## therapy_CBT:drug_joyzepam -0.78836108 0.2548161As with the normal theory estimates, the confidence interval for the interaction estimate includes zero. We should accept the null hypothesis.
As we saw in LT3, because the interaction terms between therapy and drug are not different from zero, we can remove them from the model and retain only the main effects. Lets do that now and create a new R object housing this reduced model called "linear.model2reduced"
linear.model3reduced <- lm(mood.gain ~ 1 + therapy_CBT + drug_anxifree + drug_joyzepam, data = clin.trial)
summary(linear.model3reduced)##
## Call:
## lm(formula = mood.gain ~ 1 + therapy_CBT + drug_anxifree + drug_joyzepam,
## data = clin.trial)
##
## Residuals:
## Min 1Q Median 3Q Max
## -0.3556 -0.1806 0.0000 0.1972 0.3778
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 0.2889 0.1211 2.385 0.0318 *
## therapy_CBT 0.3222 0.1211 2.660 0.0187 *
## drug_anxifree 0.2667 0.1484 1.797 0.0939 .
## drug_joyzepam 1.0333 0.1484 6.965 6.6e-06 ***
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 0.257 on 14 degrees of freedom
## Multiple R-squared: 0.8092, Adjusted R-squared: 0.7683
## F-statistic: 19.79 on 3 and 14 DF, p-value: 2.64e-05Let's also calculate F for the comparison between the full model (main effects and interactions) and the reduced model (main effects only) - just to check that the reduced model does indeed provide the best fit. As we saw in LT2, the calculation for doing this F test is:
F = ((R2full - R2reduced)/(dffull-dfreduced))/((1-R2full)/dffull) - see LT2 lecture notes for formula
We did this model comparison by hand in LT2, but the anova() function in R allows us to do this a little quicker.
anova(linear.model3reduced, linear.model3full) # ANOVA directly compares two models and returns the F value and associated significance.## Analysis of Variance Table
##
## Model 1: mood.gain ~ 1 + therapy_CBT + drug_anxifree + drug_joyzepam
## Model 2: mood.gain ~ 1 + therapy_CBT + drug_anxifree + drug_joyzepam +
## therapy_CBT * drug_anxifree + therapy_CBT * drug_joyzepam
## Res.Df RSS Df Sum of Sq F Pr(>F)
## 1 14 0.92444
## 2 12 0.65333 2 0.27111 2.4898 0.1246Our F here is small (2.48, df = 2, 14) and the associated p value is above .05 so we prefer the reduced model - there is no improvement in fit with interaction terms added. As such, we accept the null hypothesis.
Equivalence with aov()
As I am sure it is becoming clear by now, doing the same analysis with aov() tests exactly the same model - but with categorical not numerical input. To demonstrate this, lets build the same moderated linear model of mood using the aov() function and save it as a new R object called "anova.model3full". The aov() function takes categorical not numerical input for the predictors and therefore we won't use the dummy variables this time.
anova.model3full <- aov(mood.gain ~ therapy*drug, data = clin.trial)
summary(anova.model3full)## Df Sum Sq Mean Sq F value Pr(>F)
## therapy 1 0.467 0.4672 8.582 0.0126 *
## drug 2 3.453 1.7267 31.714 1.62e-05 ***
## therapy:drug 2 0.271 0.1356 2.490 0.1246
## Residuals 12 0.653 0.0544
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1As we can see here, the F value (2.49) for the interaction term is exactly the same as the F value for the full vs reduced model comparison that we just conducted using the linear model above. Thats becuase, under the bonnet, the analyses for the contribution of the interaction of therapy*drug are exactly the same. To further demonstrate this, we can call the coefficients from the aov() model.
coef(anova.model3full)## (Intercept) therapyCBT druganxifree
## 0.3000000 0.3000000 0.1000000
## drugjoyzepam therapyCBT:druganxifree therapyCBT:drugjoyzepam
## 1.1666667 0.3333333 -0.2666667And again, compare these coeffcients with the coefficents from the linear model to see that the tests are equivalent.
Now we know we can remove the interaction because it is not significant, so lets do that and save it as a new R object called "anova.model3reduced". While we are at it, lets also request the effect sizes using the etaSquared() function.
anova.model3reduced <- aov(mood.gain ~ therapy + drug, data = clin.trial)
summary(anova.model3reduced)## Df Sum Sq Mean Sq F value Pr(>F)
## therapy 1 0.467 0.4672 7.076 0.0187 *
## drug 2 3.453 1.7267 26.149 1.87e-05 ***
## Residuals 14 0.924 0.0660
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1eta_sq(anova.model3reduced, partial=TRUE)## Warning: 'eta_sq' is deprecated.
## Use 'effectsize::eta_squared()' instead.
## See help("Deprecated")## Parameter | Eta2 (partial) | 90% CI
## -----------------------------------------
## therapy | 0.34 | [0.04, 0.59]
## drug | 0.79 | [0.57, 0.87]As with the full ANOVA model, we can see that the main effects of therapy and drug are both significant (p < .05) in this reduced model. The effect sizes are also quite large - especially for drug (pη2 = 0.79). As these are omnibus tests, a significant F value only tells us that there is a difference somewhere on the factor. What F does not tell us is where those differences are, so for this we need to run the post-hoc tests of pairwise comparisons.
Post-hoc tests
The reduced linear model above suggested that there are significant main effects for therapy and the joyzepam vs others contrast. So lets go ahead and request the specific contrasts using using the TukeyHSD() function from the reduced anova R object to see where those signficant comparisons are.
TukeyHSD(anova.model3reduced)## Tukey multiple comparisons of means
## 95% family-wise confidence level
##
## Fit: aov(formula = mood.gain ~ therapy + drug, data = clin.trial)
##
## $therapy
## diff lwr upr p adj
## CBT-no.therapy 0.3222222 0.0624132 0.5820312 0.0186602
##
## $drug
## diff lwr upr p adj
## anxifree-placebo 0.2666667 -0.1216321 0.6549655 0.2062942
## joyzepam-placebo 1.0333333 0.6450345 1.4216321 0.0000186
## joyzepam-anxifree 0.7666667 0.3783679 1.1549655 0.0003934As we can see, this analysis has outputted the specific comparisons for us. Mood is higher for patients receiving CBT vs no therapy (diff = .32, 95% ci = .06, .58). Likewise, we can also see that mood is higher for those taking joyzepam vs placebo (diff = 1.03, 95% ci = .65, 1.42) and vs anxifree (diff = .77, 95% ci = .38, 1.15). There is no difference between anxifree and placebo.
How its written
We submitted the mood for each group to a 2 (therapy: CBT vs. no therapy) x 3 (drug: joyzepam vs anxifree vs placebo) between-person factoral ANOVA.
There was a main effect of therapy, F (1, 14) = 7.08, MSE = .48, p < 0.05. Mood was greater in CBT than in no therapy (mean diff = .32, 95% CI = .06, .58).
The main effect of drug was also significant, F (1, 14) = 26.15, MSE = 1.73, p < .01. Mood is higher for those taking joyzepam vs placebo (diff = 1.03, 95% ci = .65, 1.42) and vs anxifree (diff = .77, 95% ci = .38, 1.15). There is no difference between anxifree and placebo.
The two-way interaction between therapy and drug was not significant, F (1, 14) = 2.490, MSE = .14, p > 0.05.
Activity: 2 x 2 within-persons factoral ANOVA with interaction (sometimes called repeated measures factoral ANOVA)
The data
This lab activity uses the data from “Stand by your Stroop: Standing up enhances selective attention and cognitive control” (Rosenbaum, Mama, Algom, 2017). This paper asked whether sitting versus standing would influence a measure of selective attention, the ability to ignore distracting information.
They used a classic test of selective attention, called the Stroop effect. In a typical Stroop experiment, subjects name the color of words as fast as they can. The trick is that sometimes the color of the word is the same as the name of the word, and sometimes it is not.
Congruent trials occur when the color and word match. So, the correct answers for each of the congruent stimuli shown would be to say, red, green, blue and yello. Incongruent trials occur when the color and word mismatch. The correct answers for each of the incongruent stimuli would be: blue, yellow, red, green.
The Stroop effect is an example of a well-known phenomena. What happens is that people are faster to name the color of the congruent items compared to the color of the incongruent items. This difference (incongruent reaction time - congruent reaction time) is called the Stroop effect.
Many researchers argue that the Stroop effect measures something about selective attention, the ability to ignore distracting information. In this case, the target information that you need to pay attention to is the color, not the word. For each item, the word is potentially distracting, it is not information that you are supposed to respond to. However, it seems that most people can’t help but notice the word, and their performance in the color-naming task is subsequently influenced by the presence of the distracting word.
People who are good at ignoring the distracting words should have small Stroop effects. They will ignore the word, and it won’t influence them very much for either congruent or incongruent trials. As a result, the difference in performance (the Stroop effect) should be fairly small (if you have “good” selective attention in this task). People who are bad at ignoring the distracting words should have big Stroop effects. They will not ignore the words, causing them to be relatively fast when the word helps, and relatively slow when the word mismatches. As a result, they will show a difference in performance between the incongruent and congruent conditions.
The design of the study was a 2 x 2 repeated-measures design. The first predictor was congruency (congruent vs incongruent). The second predictor was posture (sitting vs. standing). The outcome was reaction time to name the word in milliseconds. There were 50 participants in the study.
The research question of this study was to ask:
Does standing up improve reaction time compared to sitting down?
It was predicted that smaller Stroop effects when people were standing up and doing the task, compared to when they were sitting down and doing the task.
The null hypothesis is:
The difference in reaction time between standing up and sitting down will be zero.
Formatting the data for repeated measures
Lets first load this data. Go to the LT3 folder, and then to the workshop folder, and find the "stroop.csv" file. Click on it and then select "import dataset". In the new window that appears, click "update" and then when the dataframe shows, click import. If you want, you can try running the code below and it might do the same thing (if not put your hand up).
stroop <- read_csv("C:/Users/tc560/Dropbox/Work/LSE/PB130/LT5/Workshop/stroop.csv")##
## -- Column specification --------------------------------------------------------
## cols(
## ID = col_double(),
## congruent_stand = col_double(),
## incongruent_stand = col_double(),
## congruent_sit = col_double(),
## incongruent_sit = col_double()
## )stroop## # A tibble: 50 x 5
## ID congruent_stand incongruent_stand congruent_sit incongruent_sit
## <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1 892. 1016. 1032. 1091.
## 2 2 702. 815. 610. 662.
## 3 3 1010. 1050. 950. 1105.
## 4 4 735. 819. 636. 867.
## 5 5 905. 1016. 903. 1024.
## 6 6 956. 954. 839. 914.
## 7 7 879. 981. 945. 1087.
## 8 8 872. 926. 884. 927.
## 9 9 876. 1033. 1062. 1213.
## 10 10 797. 933. 772. 959.
## # ... with 40 more rowsWe see there are four columns of numbers. The column names tell us whether the data is for a congruent or incongruent condition, and whether the participant was sitting or standing. Note, this data is in wide-format, not long-format. Each subject has 4 measures per row. We will need to change this to work with the data in R. So we are going to convert the data frame to long format. What we want at the end of this conversion is:
- A column for the subject variable (i.e., subject ID)
- A column for the congruency variable (i.e., congruent vs incongruent)
- A column for the posture variable (i.e., sit vs. stand)
- A column for the outcome (mean reaction time)
The best way to transform data between long and wide is to use the spread and gather functions from the tidyverse package, and the melt and cast functions, which also do some data frame transforming. The transformation from wide to long can be complicated depending on the structure of the data, and you may often find it helpful to google these functions to look for more examples of their use.
Let’s use the tidyverse gather function to change our data from wide to long.
stroop <- gather(stroop, key=Condition, value=RT, congruent_stand, incongruent_stand, congruent_sit, incongruent_sit)
stroop## # A tibble: 200 x 3
## ID Condition RT
## <dbl> <chr> <dbl>
## 1 1 congruent_stand 892.
## 2 2 congruent_stand 702.
## 3 3 congruent_stand 1010.
## 4 4 congruent_stand 735.
## 5 5 congruent_stand 905.
## 6 6 congruent_stand 956.
## 7 7 congruent_stand 879.
## 8 8 congruent_stand 872.
## 9 9 congruent_stand 876.
## 10 10 congruent_stand 797.
## # ... with 190 more rowsTake a moment to look at stroop. It is almost what we need. It is certainly in long format. There is a column for Subjects (ID), and a column for the outcome (RT), but there is only one column for both predictors (Condition), that’s no good. There are two predictors (condition and posture), we need two columns. Fortunately, the levels in the new Condition column are coded with a specific and consistent structure:
- congruent_stand
- incongruent_stand
- congruent_sit
- incongruent_sit
If only we could split these by the "_" (underscore), then we would have two columns for the congruency and the posture variable. We can do this using tstrsplit from the data.table package.
new_columns <- tstrsplit(stroop$Condition, "_", names=c("Congruency","Posture"))You can look inside new_columns to see that we succesfully made the split. Now, we just need to add them on to the stroop_long data frame using cbind().
stroop <- cbind(stroop,new_columns)
stroop## ID Condition RT Congruency Posture
## 1 1 congruent_stand 892.1429 congruent stand
## 2 2 congruent_stand 701.6111 congruent stand
## 3 3 congruent_stand 1009.7419 congruent stand
## 4 4 congruent_stand 734.6286 congruent stand
## 5 5 congruent_stand 904.8529 congruent stand
## 6 6 congruent_stand 955.9118 congruent stand
## 7 7 congruent_stand 879.2188 congruent stand
## 8 8 congruent_stand 872.3529 congruent stand
## 9 9 congruent_stand 876.3125 congruent stand
## 10 10 congruent_stand 797.3333 congruent stand
## 11 11 congruent_stand 732.4118 congruent stand
## 12 12 congruent_stand 929.1515 congruent stand
## 13 13 congruent_stand 739.1562 congruent stand
## 14 14 congruent_stand 1112.0882 congruent stand
## 15 15 congruent_stand 596.5758 congruent stand
## 16 16 congruent_stand 753.7714 congruent stand
## 17 17 congruent_stand 829.6857 congruent stand
## 18 18 congruent_stand 923.2500 congruent stand
## 19 19 congruent_stand 897.7576 congruent stand
## 20 20 congruent_stand 755.9143 congruent stand
## 21 21 congruent_stand 666.2286 congruent stand
## 22 22 congruent_stand 714.6286 congruent stand
## 23 23 congruent_stand 603.8571 congruent stand
## 24 24 congruent_stand 1042.2258 congruent stand
## 25 25 congruent_stand 793.3824 congruent stand
## 26 26 congruent_stand 784.0556 congruent stand
## 27 27 congruent_stand 724.6667 congruent stand
## 28 28 congruent_stand 811.1176 congruent stand
## 29 29 congruent_stand 768.0857 congruent stand
## 30 30 congruent_stand 900.4667 congruent stand
## 31 31 congruent_stand 688.2222 congruent stand
## 32 32 congruent_stand 835.8000 congruent stand
## 33 33 congruent_stand 751.7000 congruent stand
## 34 34 congruent_stand 884.7576 congruent stand
## 35 35 congruent_stand 752.1111 congruent stand
## 36 36 congruent_stand 741.9412 congruent stand
## 37 37 congruent_stand 705.2778 congruent stand
## 38 38 congruent_stand 756.7419 congruent stand
## 39 39 congruent_stand 870.4444 congruent stand
## 40 40 congruent_stand 750.1944 congruent stand
## 41 41 congruent_stand 857.5789 congruent stand
## 42 42 congruent_stand 793.5143 congruent stand
## 43 43 congruent_stand 940.1429 congruent stand
## 44 44 congruent_stand 815.9375 congruent stand
## 45 45 congruent_stand 677.1667 congruent stand
## 46 46 congruent_stand 823.3429 congruent stand
## 47 47 congruent_stand 728.9697 congruent stand
## 48 48 congruent_stand 721.4706 congruent stand
## 49 49 congruent_stand 811.6667 congruent stand
## 50 50 congruent_stand 788.4286 congruent stand
## 51 1 incongruent_stand 1016.5000 incongruent stand
## 52 2 incongruent_stand 815.0857 incongruent stand
## 53 3 incongruent_stand 1050.1333 incongruent stand
## 54 4 incongruent_stand 819.4000 incongruent stand
## 55 5 incongruent_stand 1016.1154 incongruent stand
## 56 6 incongruent_stand 954.2727 incongruent stand
## 57 7 incongruent_stand 981.0286 incongruent stand
## 58 8 incongruent_stand 925.7667 incongruent stand
## 59 9 incongruent_stand 1033.0882 incongruent stand
## 60 10 incongruent_stand 932.8571 incongruent stand
## 61 11 incongruent_stand 840.3611 incongruent stand
## 62 12 incongruent_stand 1007.2121 incongruent stand
## 63 13 incongruent_stand 914.7273 incongruent stand
## 64 14 incongruent_stand 1178.7308 incongruent stand
## 65 15 incongruent_stand 707.6667 incongruent stand
## 66 16 incongruent_stand 851.6970 incongruent stand
## 67 17 incongruent_stand 968.8857 incongruent stand
## 68 18 incongruent_stand 998.4242 incongruent stand
## 69 19 incongruent_stand 947.6471 incongruent stand
## 70 20 incongruent_stand 878.2500 incongruent stand
## 71 21 incongruent_stand 787.9118 incongruent stand
## 72 22 incongruent_stand 829.5000 incongruent stand
## 73 23 incongruent_stand 682.1471 incongruent stand
## 74 24 incongruent_stand 1099.6667 incongruent stand
## 75 25 incongruent_stand 871.5312 incongruent stand
## 76 26 incongruent_stand 920.8333 incongruent stand
## 77 27 incongruent_stand 862.8611 incongruent stand
## 78 28 incongruent_stand 929.6250 incongruent stand
## 79 29 incongruent_stand 841.8000 incongruent stand
## 80 30 incongruent_stand 1109.8182 incongruent stand
## 81 31 incongruent_stand 784.3714 incongruent stand
## 82 32 incongruent_stand 878.0000 incongruent stand
## 83 33 incongruent_stand 826.4000 incongruent stand
## 84 34 incongruent_stand 1010.7059 incongruent stand
## 85 35 incongruent_stand 754.5714 incongruent stand
## 86 36 incongruent_stand 746.6111 incongruent stand
## 87 37 incongruent_stand 771.9714 incongruent stand
## 88 38 incongruent_stand 885.7353 incongruent stand
## 89 39 incongruent_stand 941.9143 incongruent stand
## 90 40 incongruent_stand 848.2353 incongruent stand
## 91 41 incongruent_stand 933.1250 incongruent stand
## 92 42 incongruent_stand 896.4375 incongruent stand
## 93 43 incongruent_stand 1048.1852 incongruent stand
## 94 44 incongruent_stand 982.4286 incongruent stand
## 95 45 incongruent_stand 758.1714 incongruent stand
## 96 46 incongruent_stand 844.5000 incongruent stand
## 97 47 incongruent_stand 833.8571 incongruent stand
## 98 48 incongruent_stand 849.7429 incongruent stand
## 99 49 incongruent_stand 1020.6471 incongruent stand
## 100 50 incongruent_stand 806.5000 incongruent stand
## 101 1 congruent_sit 1031.9600 congruent sit
## 102 2 congruent_sit 610.4722 congruent sit
## 103 3 congruent_sit 949.8788 congruent sit
## 104 4 congruent_sit 636.3333 congruent sit
## 105 5 congruent_sit 902.7273 congruent sit
## 106 6 congruent_sit 839.3611 congruent sit
## 107 7 congruent_sit 945.0571 congruent sit
## 108 8 congruent_sit 883.5143 congruent sit
## 109 9 congruent_sit 1062.2400 congruent sit
## 110 10 congruent_sit 771.5833 congruent sit
## 111 11 congruent_sit 754.2941 congruent sit
## 112 12 congruent_sit 905.8571 congruent sit
## 113 13 congruent_sit 771.2353 congruent sit
## 114 14 congruent_sit 1031.3636 congruent sit
## 115 15 congruent_sit 660.1765 congruent sit
## 116 16 congruent_sit 777.6765 congruent sit
## 117 17 congruent_sit 949.8077 congruent sit
## 118 18 congruent_sit 912.0000 congruent sit
## 119 19 congruent_sit 983.6129 congruent sit
## 120 20 congruent_sit 755.7429 congruent sit
## 121 21 congruent_sit 759.0000 congruent sit
## 122 22 congruent_sit 727.6111 congruent sit
## 123 23 congruent_sit 634.4242 congruent sit
## 124 24 congruent_sit 1011.5938 congruent sit
## 125 25 congruent_sit 864.5278 congruent sit
## 126 26 congruent_sit 720.2778 congruent sit
## 127 27 congruent_sit 724.6111 congruent sit
## 128 28 congruent_sit 734.9697 congruent sit
## 129 29 congruent_sit 779.6857 congruent sit
## 130 30 congruent_sit 843.7241 congruent sit
## 131 31 congruent_sit 751.6000 congruent sit
## 132 32 congruent_sit 905.6364 congruent sit
## 133 33 congruent_sit 871.9130 congruent sit
## 134 34 congruent_sit 863.6333 congruent sit
## 135 35 congruent_sit 707.2286 congruent sit
## 136 36 congruent_sit 656.0833 congruent sit
## 137 37 congruent_sit 738.6765 congruent sit
## 138 38 congruent_sit 755.7059 congruent sit
## 139 39 congruent_sit 988.8286 congruent sit
## 140 40 congruent_sit 681.0000 congruent sit
## 141 41 congruent_sit 816.6333 congruent sit
## 142 42 congruent_sit 782.4375 congruent sit
## 143 43 congruent_sit 1025.3125 congruent sit
## 144 44 congruent_sit 829.3429 congruent sit
## 145 45 congruent_sit 708.0278 congruent sit
## 146 46 congruent_sit 776.3438 congruent sit
## 147 47 congruent_sit 768.7273 congruent sit
## 148 48 congruent_sit 789.7222 congruent sit
## 149 49 congruent_sit 943.7879 congruent sit
## 150 50 congruent_sit 800.2000 congruent sit
## 151 1 incongruent_sit 1090.7778 incongruent sit
## 152 2 incongruent_sit 662.1944 incongruent sit
## 153 3 incongruent_sit 1105.4545 incongruent sit
## 154 4 incongruent_sit 866.5714 incongruent sit
## 155 5 incongruent_sit 1024.0909 incongruent sit
## 156 6 incongruent_sit 914.2812 incongruent sit
## 157 7 incongruent_sit 1087.1471 incongruent sit
## 158 8 incongruent_sit 926.7742 incongruent sit
## 159 9 incongruent_sit 1213.2857 incongruent sit
## 160 10 incongruent_sit 958.7500 incongruent sit
## 161 11 incongruent_sit 872.1429 incongruent sit
## 162 12 incongruent_sit 1032.5758 incongruent sit
## 163 13 incongruent_sit 875.6875 incongruent sit
## 164 14 incongruent_sit 1103.8125 incongruent sit
## 165 15 incongruent_sit 723.5429 incongruent sit
## 166 16 incongruent_sit 884.0000 incongruent sit
## 167 17 incongruent_sit 1172.5862 incongruent sit
## 168 18 incongruent_sit 1008.3333 incongruent sit
## 169 19 incongruent_sit 1005.9130 incongruent sit
## 170 20 incongruent_sit 812.9722 incongruent sit
## 171 21 incongruent_sit 890.6562 incongruent sit
## 172 22 incongruent_sit 918.8611 incongruent sit
## 173 23 incongruent_sit 679.1818 incongruent sit
## 174 24 incongruent_sit 1086.5806 incongruent sit
## 175 25 incongruent_sit 959.0938 incongruent sit
## 176 26 incongruent_sit 880.6944 incongruent sit
## 177 27 incongruent_sit 869.7429 incongruent sit
## 178 28 incongruent_sit 910.4000 incongruent sit
## 179 29 incongruent_sit 890.5714 incongruent sit
## 180 30 incongruent_sit 1040.1000 incongruent sit
## 181 31 incongruent_sit 851.0857 incongruent sit
## 182 32 incongruent_sit 994.6176 incongruent sit
## 183 33 incongruent_sit 945.2381 incongruent sit
## 184 34 incongruent_sit 1007.6786 incongruent sit
## 185 35 incongruent_sit 764.9706 incongruent sit
## 186 36 incongruent_sit 743.0294 incongruent sit
## 187 37 incongruent_sit 879.2778 incongruent sit
## 188 38 incongruent_sit 801.3548 incongruent sit
## 189 39 incongruent_sit 1112.3939 incongruent sit
## 190 40 incongruent_sit 867.8000 incongruent sit
## 191 41 incongruent_sit 931.6667 incongruent sit
## 192 42 incongruent_sit 842.7742 incongruent sit
## 193 43 incongruent_sit 1198.3333 incongruent sit
## 194 44 incongruent_sit 963.8000 incongruent sit
## 195 45 incongruent_sit 849.2353 incongruent sit
## 196 46 incongruent_sit 953.0833 incongruent sit
## 197 47 incongruent_sit 912.4194 incongruent sit
## 198 48 incongruent_sit 957.4722 incongruent sit
## 199 49 incongruent_sit 1109.7407 incongruent sit
## 200 50 incongruent_sit 886.5294 incongruent sitLook at the stroop data frame and you will find that we have added two new columns, one that codes for Congruency, and the other that codes for posture.
After all of this data transformation you should be familiar with the predictors:
- Congruency with 2 levels: congruent vs.incongruent
- Posture with 2 levels: stand vs. sit
There is only one outcome that we look at, which is the mean reaction time to name the color (RT).
Conduct the ANOVA
Becasue of the way the data is structured in long format, we cannot run a repeated measures ANOVA using the linear model, but please see the postscript of this notebook for an example of how the tests are equivalent.
Therefore, we will conduct a repeated measures ANOVA using aov(). This way, we will be able capitilize on the major benefit provided by the repeated measures design. We can remove the variance due to individual subjects from the error terms we use to calculate F-values for each main effect and interaction. If we just used the linear model on this long dataset, we would not be able to remove this variance (see below for more information).
Remember the formula for the 2 x 2 between-subjects factoral ANOVA with interaction above, I’ll remind you:
aov(outcome ~ predictor + moderator + predictor*moderator, dataframe)
To do the same for a repeated measures design, the code looks like this:
aov(outcome ~ predictor + moderator + predictormoderator + Error(ID/(predictor + moderator + predictormoderator)), dataframe)
- outcome = name of dependent variable
- predictor = name of first preditor variable
- moderator = name of second predictor variable
- ID = name of the subject variable, coding the means for each subject in each condition
- dataframe = name of the long-format data frame
We have added + Error(Subject/predictor + moderator + predictor*moderator). This tells R to use the appropriate degrees of freedom for the repeated measures ANOVA (i.e., each effect is conditioned on ID - that is, estimated once for each individual).
Here is what our formula will look like:
aov(RT ~ Congruency + Posture + CongruencyPosture + Error(Subject/(Congruency + Posture + CongruencyPosture)), data = stroop)
Go ahead and write that code and request the summary:
anova.model4 <- aov(?? ~ ?? + ?? + C?? + Error(as.factor(ID)/(Congruency + Posture + Congruency*Posture)), data = ??)
summary(??) Is there a main effect of Congruency?
Is there a main effect of Posture?
Is there two-way interaction between Congruency and Posture?
Post-hoc tests
We can also request the means for the conditions and the paired contrasts. Remember that the F tests are omnibus tests, they don't tell us anything about the specific comparisons. Now there are a few comparisons we could test, but with a significant interaction term the only real comparisons of interest are those that concern the Congruency * Posture interaction. So we can ask:
Was the stroop effect only for the sitting condition statistically signficant? In other words, was the difference in mean RT between the incongruent and congruent conditions unlikely under the null (or unlikely to be produced by chance).
Was the Stroop effect only for the standing condition statistically signficant? In other words, was the difference in mean RT between the incongruent and congruent conditions unlikely under the null (or unlikely to be produced by chance).
We do these comparisons using emmeans.
emmeans(anova.model4, pairwise ~ Congruency, adjust='bonferroni')
emmeans(anova.model4, pairwise ~ Posture, adjust='bonferroni')
emmeans(anova.model4, pairwise ~ Congruency|Posture, adjust='bonferroni')What is the mean difference in reaction time for the sitting condition?
What is the mean difference in reation time for the standing condition?
Are these differences statistically significant using paired t-test?
We can see that the paired contrasts are significant for both conditions - reation time was slower in incongruent condition for both standing and sitting. But this effect appears to be mitigated somewhat when the pariticipants were standing.
How its written
We submitted the mean reaction times for each subject in each condition to a 2 (Congruency: congrueny vs. incongruent) x 2 (Posture: Standing vs. Sitting) repeated measures ANOVA.
There was a main effect of Congruency, F (1, 49) = 342.45, MSE = 1684.39, p < 0.001. Mean reaction times were slower for incongruent (922 ms) than congruent groups (815 ms).
The main effect of Posture was significant, F (1, 49) = 7.33, MSE = 4407.09, p =.009. Mean reaction times were slower for sitting (881 ms) than standing groups (855 ms).
The two-way interaction between Congruency and Posture was significant, F (1, 49) = 8.96, MSE = 731.82, p < 0.004. The Stroop effect was 23 ms smaller in the standing (mean diff = -119ms, t = -17.10, p <.01) than sitting (mean diff = -96, t = 13.80, p <.01) conditions.
Post script for further learning: 2 x 2 mixed factoral ANOVA with interaction as a linear model
The data
To demonstrate mixed 2 x 2 ANOVA with an interaction, we are going to use the data from Experiment 3 of; Zhang, T., Kim, T., Brooks, A. W., Gino, F., & Norton, M. I. (2014). A "present" for the future: The unexpected value of rediscovery. Psychological Science, 25, 1851-1860.
The premise of this study was that people often keep diaries to help them remember and contemplate the events of their lives. Months or years later, when people look back through their diary entries, they often gain insights about the overall meaningfulness of these events, as well as their emotional reactions to them.
With this in mind, Zhang et al. (2014) sought to examine whether individuals are more likely to mispredict the value of rediscovering ordinary events than to mispredict the value of rediscovering extraordinary events, which are more memorable. Becuase of this, it was predicted that ordinary events will come to be perceived as more extraordinary over time, whereas perceptions of extraordinary events will not change across time.
To test this hypothesis, the authors recruited individuals who were currently involved in romantic relationships, and asked half of the participants to write about an extraordinary day with their romantic partner (Valentine’s Day), and the other half to write about an ordinary day with their romantic partner (what happened two days ago). The authors then asked participants rate the degree of extraordinariness on a scale of 1 to 7 (1 = extremely ordinary, 4 = neither ordinary nor extraordinary, 7 = extraordinary) for their diary entry.
Three months later, the authors contacted all of the participants, and had them read their description of the extraordinary or ordinary day, and then rate how extraordinary the event was in retrospect using the same scale. This is a classic mixed 2 x 2 ANOVA with an interaction. The outcome in this case is ratings of extraordinariness and the predictors are time with two levels (i.e., time 1 and time 2) and condition with two levels (i.e., ordinary or extraordinary day). The design is mixed because time is a within-person factor and condition is a between person factor.
Becasue of the mixed nature of this design, the data is structured slightly differently to how we have been working with to date. Instead of being in horizontal format with each participants score for each variable listed in each row, the data for a mixed design needs to be in vertical format with each participant's score for each time point listed in each row. Lets load the dataset into R and we'll look at what this means.
Go to the LT3 folder, and then to the workshop folder, and find the "extraordinary.csv" file. Click on it and then select "import dataset". In the new window that appears, click "update" and then when the dataframe shows, click import. If you want, you can try running the code below and it might do the same thing (if not put your hand up).
extraordinary <- read_csv("C:/Users/tc560/Dropbox/Work/LSE/PB130/LT5/Workshop/extraordinary.csv")##
## -- Column specification --------------------------------------------------------
## cols(
## Condition = col_double(),
## ID = col_double(),
## time = col_double(),
## extraordinary = col_double()
## )View(extraordinary)If you go to the data file and click on the "ID" column, it will sort the data file from low to high. As you will see, when you sort the data by ID, each individual has 2 data rows. The first is for the rating of extraordinariness at time point 1 (coded 0) and the second is for the rating of extraordinariness at time point 2 (Coded 1). This is the within-person factor. The condition that the person belongs to (i.e., ordinary coded 0 or extraordinary coded 1) is the same across each time point becuase this is the between-person factor - the factor that differs between persons, but not within them. Structured this way, the linear model can estiamte the effect of time (i.e., differences between the time points) and condition (i.e., the differences between the conditions) simultaneously.
As always, before we delve into this topic lets just clarify the research question and null hypothesis we are testing:
Research Question - Is the effect of time on ratings of event extrordinariness moderated by experimental condition?
Null Hypothesis - The interaction of time and condition on event extraordinariness will be zero.
Setting up the linear model
Now lets set up the linear model. And we don't need to intoduce anything new here - we are just building a moderated regression model in the same way as we did in LT3 - but this time we are using categorical predictors rather than continuous. For this, we add the preditors and their interaction term in the lm() function. So lets add do that now to build our a linear model of extraordinariness and create a new R object called "linear.model2"
linear.model4 <- lm(extraordinary ~ 1 + time + Condition + time*Condition, data=extraordinary)
summary(linear.model4)##
## Call:
## lm(formula = extraordinary ~ 1 + time + Condition + time * Condition,
## data = extraordinary)
##
## Residuals:
## Min 1Q Median 3Q Max
## -3.5152 -0.7344 0.0625 1.0625 3.2656
##
## Coefficients:
## Estimate Std. Error t value Pr(>|t|)
## (Intercept) 2.7344 0.1623 16.845 < 2e-16 ***
## time 1.2031 0.2296 5.241 3.34e-07 ***
## Condition 1.6141 0.2278 7.085 1.34e-11 ***
## time:Condition -1.0365 0.3222 -3.217 0.00146 **
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Residual standard error: 1.299 on 256 degrees of freedom
## Multiple R-squared: 0.2249, Adjusted R-squared: 0.2158
## F-statistic: 24.76 on 3 and 256 DF, p-value: 4.216e-14We already know that in a linear model with an interaction term, the estimates for b1 and b2 become conditional effects - differences between the level of the predictor when the other predictor is 0. So here the intercept estimate is the mean extraordinary rating for the people in the ordinary condition (coded 0) at time 1 (coded 0). The slope for time is the boost needed to the intercept to find the mean extraordinary rating for people in the ordinary condition (coded 0) at time point 2 (coded 1). The slope for condition is the boost needed to the intercept to find the mean extraordinary rating for people in the extraordinary condition (coded 1) at time point 1 (coded 0).
As we know from LT3, these main effects, as we have been calling them, are irrelevant in the presence of a significant interaction term because they will depend on the level of the moderator. In this case, the interaction of time and condition means that the effect of time on extraordinariness depends on the condition that participants were assigned to. I don't want you to focus on the t ratios and p values here becuase this is a mixed design and therefore the errors in the linear model are wrong (more below). For now, lets just move forward to probing this interaction.
Probing the interaction
Okay, so just like moderation analysis, the slope for the interaction term doesn't really tell us a great deal beyond the fact that the effect of the predictor on the outcome depends on the level of the moderator. In order to better understand our interaction, we need to probe it. By now, we should know how to do this with categorical variables. We're just going to examine the conditional effects of time on ratings of extrodinariness across the two levels of our moderator. As we saw in LT3, we can easily do this with the pickpoint() function.
pickapoint(linear.model4, dv='extraordinary', iv='time', mod='Condition')## Call:
## pickapoint(model = linear.model4, dv = "extraordinary", iv = "time",
## mod = "Condition")
## Conditional effects of time on extraordinary at values of Condition
## Condition Effect SE t p llci ulci
## 0 1.2031250 0.229561 5.2409818 3.350795e-07 0.7510481 1.6552019
## 1 0.1666667 0.226056 0.7372803 4.616298e-01 -0.2785079 0.6118412
##
## Values for quantitative moderators are the mean and plus/minus one SD from the mean
## Values for dichotomous moderators are the two values of the moderatorNow we are getting somewhere! Consisitent with the interaction term, we can see that the effect of time on ratings of extraordinariness depend on what condition the participants belong to. In the ordinary condition, we can see that the mean diffence between time 1 and time 2 ratings of extraordiness increased by 1.2 points. However, for people randomly assigned to the extraordinalry condition, the difference between time 1 and time 2 ratings of extraordinariness is much smaller - only 0.17.
Plotting the interaction
To get a better understading of this moderation, we can plot it. For this, I'm going to create a new data object called data thast will contain the means and standard errors for each condition, at each time point so that I can then plot them on an interaction plot. As such, I will use ggplot() this time rather than interation.plot() as we did in LT3 becuase I with the standard errors, can plot the confidence intervals around the means for each condition at each time point. Lets go ahead and create that plot.
data <- extraordinary %>%
group_by(time, Condition) %>%
summarise(extra_mean = mean(extraordinary), extra_se = psych::describe(extraordinary)$se) ## this first chunk creates a new dataset called "data" which summarises the means and standard errors for each condition at each time point. Find the "data" object in your R environment and check it out!## `summarise()` regrouping output by 'time' (override with `.groups` argument)data %>%
ggplot(aes(x=as.factor(time), y=extra_mean, colour=as.factor(Condition))) + # I am now plotting time against the extraordinary rating means for each time point across each condition. I am forcing the time and condition variables to factors so that R does not interpret them as continuous variables
geom_line(aes(group=as.factor(Condition))) +
geom_point() +
geom_errorbar(aes(ymin=extra_mean-1.96*extra_se, ymax=extra_mean+1.96*extra_se), width=.1) + # I am adding the error bars that depict the upper and lower confidence from +/- 1.96 SE of the means
labs(x = "Time",
color = "Condition",
y = "Extraordinariness") +
theme_classic()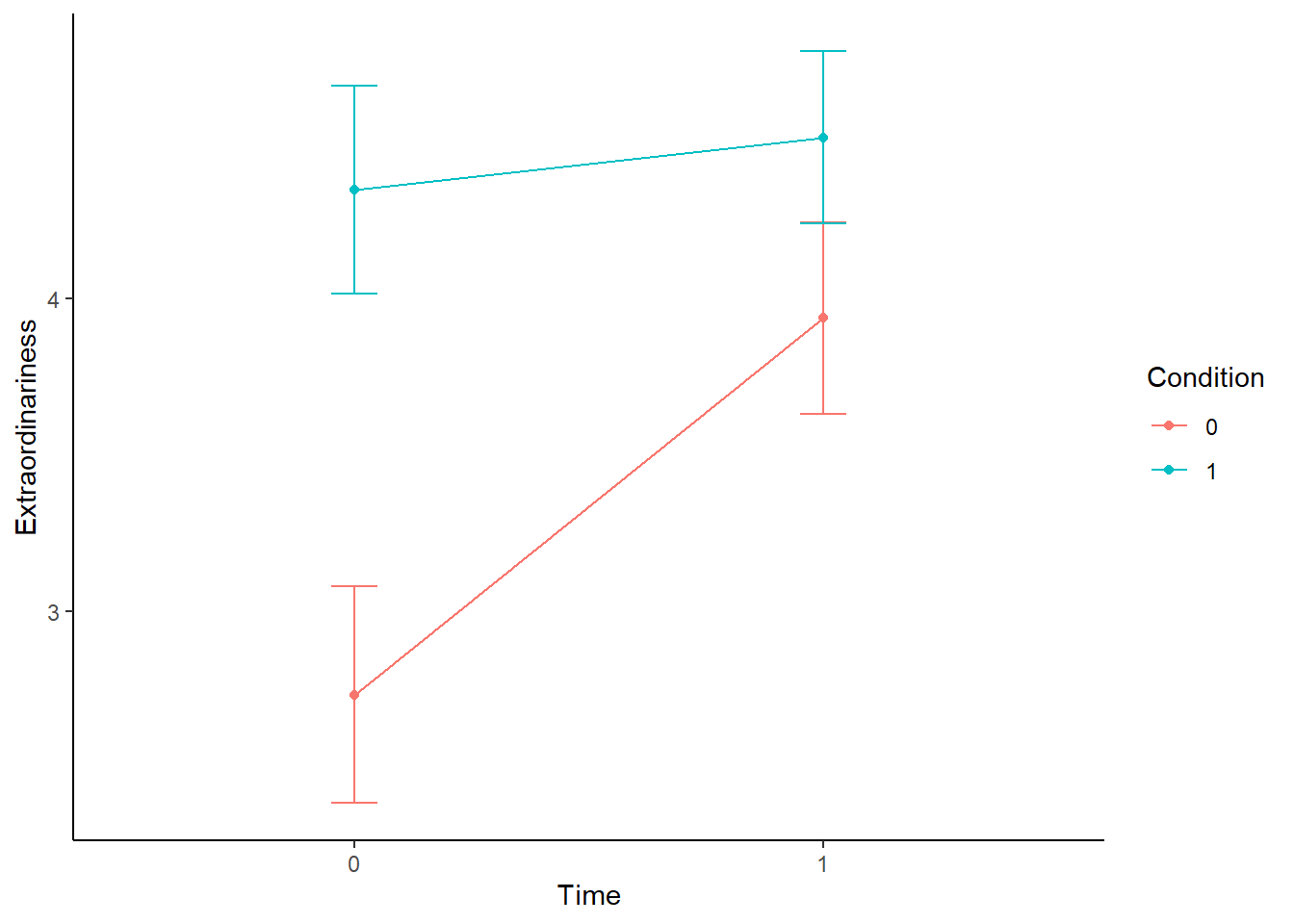
We can see clearly here what is happening in the data. Ordinary experiences were perceived as far more extraordinary at Time 2 than at Time 1, whereas these ratings for the extraordinary experiences did not differ between Time 1 and Time 2. This is precicely the hypothesis that Zhang et al had. Ordinary events come to be perceived as more extraordinary over time, whereas perceptions of extraordinary events do not change across time.
Equivalence with aov()
Again, I want to show you equivalence of the lm() with aov() for this mixed 2 x 2 ANOVA to further demonstrate how ANOVA is just a special case of regression. Special in that the predictor variables are categorical and not continuous.
I said above that lm() and aov() are both appropriate methods for anaysing the 2 x 2 ANOVA. However, when there is a mixed deisgn, like this one, aov() should ALWAYS be used. Why? Think back to the coefficients for the linear model and remember I said that we cannot interpret the t values and p values becuase the error portion of the model is wrong? Well thats becuase when we stacked the data into long format we doubled the sample size (i.e., each person has 2 rows, one for time 1 and one for time 2) and the lm() function has no way of knowing that those additional observations are actually grouped by ID. It therefore assumes the sample size is 260 rather than 130 and, as such, overestimates the degrees of freedom in the residual. Thats why we cannot rely on the lm() for null hypothesis significance testing.
But this said, the analyses are equivalent and the focal coefficient - the estimate for the interaction - will be identical. For ease, I'm going to run the supernova for the linear model and the summary for the ANOVA model to demonstrate this.
supernova(linear.model4)## Analysis of Variance Table (Type III SS)
## Model: extraordinary ~ 1 + time + Condition + time * Condition
##
## SS df MS F PRE p
## -------------- --------------- | ------- --- ------ ------ ------ -----
## Model (error reduced) | 125.281 3 41.760 24.764 0.2249 .0000
## time | 46.320 1 46.320 27.468 0.0969 .0000
## Condition | 84.654 1 84.654 50.200 0.1639 .0000
## time:Condition | 17.452 1 17.452 10.349 0.0389 .0015
## Error (from model) | 431.704 256 1.686
## -------------- --------------- | ------- --- ------ ------ ------ -----
## Total (empty model) | 556.985 259 2.151anova.model4 <- aov(extraordinary ~ as.factor(time)*as.factor(Condition) + Error(as.factor(ID)/as.factor(time)), data = extraordinary)
summary(anova.model4) ## the Error addition to the ANOVA model tells R that this is a mixed design and that time is the within-person factor with each person categorised by their ID##
## Error: as.factor(ID)
## Df Sum Sq Mean Sq F value Pr(>F)
## as.factor(Condition) 1 78.04 78.04 35.31 2.5e-08 ***
## Residuals 128 282.94 2.21
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
##
## Error: as.factor(ID):as.factor(time)
## Df Sum Sq Mean Sq F value Pr(>F)
## as.factor(time) 1 29.78 29.785 25.63 1.41e-06 ***
## as.factor(time):as.factor(Condition) 1 17.45 17.452 15.02 0.000169 ***
## Residuals 128 148.76 1.162
## ---
## Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1Of noting here is the degrees of freedom in the total model and - by extention - the error. In the linear model it is overestimated (i.e., 259) but in the ANOVA model it is correct (i.e., 128) because we have conditioned the between person effects on the within person condition. A mixed factoral ANOVA first outputs the main effect of condition. This is the overall effect of condition on extraordinariness ratings irrespective of time. Those in the extraordinary condition rated the events as more extraodinary overall, irrespective of time point. It then outputs the main effect of time, irrespecitve of condition. Here, experiences seemed more extraordinary overall at Time 2 than they did 3 months earlier, at Time 1, irrespecitve of what condition the participants were in. Sound familiar? Thats right, these are the same as unique effects in regression.
Importantly, however, the ANOVA also outputs the interaction between time and condition, F(1, 128) = 15.02, p < .001. And this, of course, is the focal effect of interest. We can interpret the F ratio and P value for this effect becuase the degrees of freedom in the error portion of the model are correct. And, as we can see, the interaction is significant. What I would like you note here is the symatery between the lm() and aov(). The sum of squares for the interaction term is exactly the same in the linear model and the ANOVA model (17.45). The F ratio and p value is wrong becuase there is no adjustment to the error in the lm(), but the mechanics under the hood are exactly the same.
Post-hoc testing
As a result of the significant interation term, we should conduct our multiple comparisons by conditioning the effect of time on the experimental condition. We do this in the emmeans() function using the vertical bar |. The vertical bar reads as meaning conditional. Here we will condition the effect of time on experimental condition using |. Lets go ahead and do that now.
extraordinary$time <- factor(extraordinary$time, levels = c("1", "0"))
emmeans(anova.model4, pairwise ~time)## Warning in model.frame.default(formula, data = data, ...): variable 'time' is
## not a factor## Note: re-fitting model with sum-to-zero contrasts## NOTE: Results may be misleading due to involvement in interactions## $emmeans
## time emmean SE df lower.CL upper.CL
## 1 4.23 0.114 233 4.01 4.46
## 0 3.55 0.114 233 3.33 3.77
##
## Results are averaged over the levels of: Condition
## Warning: EMMs are biased unless design is perfectly balanced
## Confidence level used: 0.95
##
## $contrasts
## contrast estimate SE df t.ratio p.value
## 1 - 0 0.685 0.134 128 5.121 <.0001
##
## Results are averaged over the levels of: Conditionemmeans(anova.model4, pairwise ~Condition)## Warning in model.frame.default(formula, data = data, ...): variable 'time' is
## not a factor## Note: re-fitting model with sum-to-zero contrasts
## NOTE: Results may be misleading due to involvement in interactions## $emmeans
## Condition emmean SE df lower.CL upper.CL
## 0 3.34 0.13 128 3.09 3.6
## 1 4.44 0.13 128 4.18 4.7
##
## Results are averaged over the levels of: time
## Warning: EMMs are biased unless design is perfectly balanced
## Confidence level used: 0.95
##
## $contrasts
## contrast estimate SE df t.ratio p.value
## 0 - 1 -1.1 0.184 128 -5.942 <.0001
##
## Results are averaged over the levels of: timeemmeans(anova.model4, pairwise ~time|Condition)## Warning in model.frame.default(formula, data = data, ...): variable 'time' is
## not a factor## Note: re-fitting model with sum-to-zero contrasts## $emmeans
## Condition = 0:
## time emmean SE df lower.CL upper.CL
## 1 3.95 0.162 234 3.63 4.26
## 0 2.74 0.162 234 2.42 3.06
##
## Condition = 1:
## time emmean SE df lower.CL upper.CL
## 1 4.52 0.161 233 4.21 4.84
## 0 4.36 0.161 233 4.04 4.67
##
## Warning: EMMs are biased unless design is perfectly balanced
## Confidence level used: 0.95
##
## $contrasts
## Condition = 0:
## contrast estimate SE df t.ratio p.value
## 1 - 0 1.203 0.191 128 6.313 <.0001
##
## Condition = 1:
## contrast estimate SE df t.ratio p.value
## 1 - 0 0.167 0.188 128 0.888 0.3762The way these contrasts are calcualated is pre-post and therefore the estimates should be reversed to reflect the direction of effects (i.e., negative vlaues indicate increases and vice versa). I have done this in the first line of code above. Of noting is that the point estimate for the contrasts reveal the story: the increase in ratings of extraordinariness are larger for the oridinary group (mean=1.20, SE=0.19, t=6.31) than for the extraordinary group (mean=.17, SE=0.19, t=.89).
How its written
We submitted the extrodinariness scores at each time point across each group to a 2 (time: pre vs. post) x 2 (group: ordinary vs extraordinary) mixed factorial ANOVA.
There was a main effect of time, F (1, 8) = 8.89, MSE = 14.45, p < 0.05, pn^2 = .53. More differences were observed post-intervention than pre-intervention (mean diff = 1.7, SE = .57, t = 2.98, p < .05).
The main effect of condition was also significant; F (1, 8) = 70.10, MSE = 110.45, p < .01, pn^2 = .90. Less differences were observed in the control condition versus the experimental condition (diff = -4.7, SE = .56, t = -8.37, p < .05).
The two-way interaction between time and condition was significant, F (1, 8) = 58.70, MSE = 92.45, p < 0.01, pn^2= .88. The main effect of time on differences spotted was positive in the experimental condition (pre-post diff = 6.0, SE=0.80, t=7.5, p <.01) but negative in the control condition (pre-post diff = -2.6, SE=0.80, t=-3.25, p <.05).